Как подобрать автоматический выключатель
Автоматический выключатель — устройство, обеспечивающее защиту Вашего дома, электроники и Ваших близких от поражения электрическим током. В нормальных условиях, когда работа всех приборов и проводки проходит в обычном режиме, выключатель проводит через себя электрический ток. Но в случае когда по тем или иным причинам сила тока превысила номинальные значения (подключена нагрузка больше рассчитанной, вследствие неисправности электроприборов или электроцепей возникло короткое замыкание), срабатывают расцепители автоматического выключателя и размыкают цепь.
В модульных автоматических выключателях обычно стоят два типа расцепителей:
- Тепловой расцепитель — срабатывающий при токах перегрузки. Конструктивно представляет из себя биметаллическую пластину, которая при нагревании благодаря свойствам материала распрямляется. В зависимости от величины номинального тока регулируется нагреваемая часть пластины.

- Электромагнитный расцепитель устройство срабатывающее при токах короткого замыкания, которые кратно превышают номинальный ток автоматического выключателя.

Для выбора модульного автоматического выключателя
необходимо определиться со следующими параметрами:
Количество полюсов автомата
- Однополюсные автоматические выключатели устанавливаются в однофазной цепи. При этом однополюсные автоматы устанавливаются непосредственно на фазу, и защищают отходящие линии, обычно розеточные или осветительные линии.
- Трёхполюсные выключатели устанавливаются в трехфазной сети обычно в качестве вводных автоматов или для защиты трехфазных потребителей.
Ток перегрузки автоматического выключателя
Обычно вводной автомат ставят на ток, согласно выделенной мощности на квартиру или до.
При однофазной сети
I=P/U например, на квартиру выделено 10кВт, значит вводной автомат ставим 10000Вт/220В =45,5 округляем до ближайшего меньшего =берем автомат на 40А.
При трехфазной сети
I=P/U*1.7 где 1,7 корень из 3. Допустим на квартиру выделено 30кВт -30000Вт/380В*1,7= 45,5 округляем, и выбираем трехполюсный автомат на 40А)
Для подбора автоматов на отходящих линиях необходимо выбирать в зависимости от сечения провода, который установлен на защищаемой линии. (В случае если у Вас на данной линии находится несколько потребителей).
В случае, если на защищаемой линии один потребитель (например водонагреватель) устанавливают автомат, исходя из мощности устройства.
|
Сечение токопроводящей жилы, мм |
Ток *, А, для проводов и кабелей |
||
|
|
одножильных |
двухжильных |
трехжильных |
|
1,5 |
23 |
19 |
19 |
|
2,5 |
30 |
27 |
25 |
|
4 |
41 |
38 |
35 |
|
6 |
50 |
50 |
42 |
|
10 |
80 |
|
55 |
Тип характеристики срабатывания при КЗ
- В 3-5 предназначены для защиты активных нагрузок и протяженных линий освещения с системами заземления TN и IT (розетки, освещение).
- С 5-10 предназначены для защиты цепей с активной и индуктивной нагрузкой с низким импульсным током (для офисных и жилых помещений)
- D 10-20 используется при нагрузках с высокими импульсными (пусковыми) токами и повышенном токе включения (низковольтные трансформаторы, ламы-разрядники, подъемные механизмы, насосы)
- K 8-15 активно-индуктивная нагрузка, эл.двигатели, трансформаторы
- Z 2-3 электроника

Обычно в квартиру ставят автоматические выключатели с характеристикой С.
Наибольшая отключающая способность (ПКС) автоматов
— максимальный электрический ток, который автоматический выключатель может расцепить. Здесь принцип следующий: ПКС рассчитывается из максимального тока, который может возникнуть при коротком замыкании отходящих проводов. Вводной автомат в квартиру должен быть по Госту минимум на 6 кА, автоматические выключатели на розеточную группу и освещение могут быть на 4,5 кА. В Европе автоматические выключатели на 4,5 кА запрещены.
Количество автоматов.
Обычно в распределительном щите устанавливают вводный автомат, автомат на розеточные линии на 2-3 комнаты, автомат на осветительные линии (наверно лучше по одному автомату на комнату), отдельно по автомату на мощных потребителей электроэнергии, калорифер, стиральную машину и т.д.
При комплектации наших клиентов, мы обычно рекомендуем модульные автоматы производства ABB серии S200 (ПКС 6кА) или Sh300 (ПКС 4,5кА) или Acti9 Schneider Electric. Строители при возведении новых домов устанавливают обычно автоматы производства ИЭК. Поэтому если в Вашей новой квартире установлены автоматы фирмы ИЭК, то Вы можете предположить какая у Вас установлена проводка внутри стен, марку и качество бетона и т.д.
Ничего не найдено для Apple Touch Icon 120X120 Precomposed Png
Выключатели
Правильный подбор расцепителя автоматического выключателя защитит электрооборудование, СБТ и разводку распределительной сети от перегруза
Электрооборудование и безопасность
 При наличии в семье маленьких детей
При наличии в семье маленьких детей
Светильники
Виды точечных светильников, их предназначение для ПВХ потолков и ГКЛ конструкций. Правильный монтаж с
Электрооборудование и безопасность
Популярность инфракрасного пола растет за счет его преимуществ над другими вариантами. Благодаря современным технологиям
Светильники
Точечные светильники – споты улучшают яркость освещения, без возникновения теней. Равномерно распределив их по
Равномерно распределив их по
Розетки
Выбор розетки и выключателя необходимо проводить с учетом специфики использования помещения, репутации производителя соответствующего
Автомат вводной: особенности выбора вводного автомата
При подаче электричества в квартиру на этажном электрощите могут быть установлены следующие аппараты коммутации ввода:
Вводной автомат (ВА) – это автоматический выключатель подачи электричества от питающей сети к объекту, если возникает перегрузка в цепи, или произошло короткое замыкание (КЗ). От перечисленных аппаратов он отличается большей величиной номинального тока. На фото изображен щит с расположенным в нем сверху вводным автоматом.
Щит с автоматическим выключателем
Правильнее называть устройство – вводный автоматический выключатель. Поскольку он ближе других устройств находится к воздушной линии, аппарат должен обладать повышенной коммутационной стойкостью (ПКС), характеризующей нормальное срабатывание устройства при возникновении КЗ (максимальный ток, при котором автоматический выключатель способен хотя бы однократно разомкнуть электрическую цепь). Показатель указывается на маркировке прибора.
Поскольку он ближе других устройств находится к воздушной линии, аппарат должен обладать повышенной коммутационной стойкостью (ПКС), характеризующей нормальное срабатывание устройства при возникновении КЗ (максимальный ток, при котором автоматический выключатель способен хотя бы однократно разомкнуть электрическую цепь). Показатель указывается на маркировке прибора.
Типы автоматов ввода
Подача электричества к объекту зависит от его потребностей и схемы электросети. При этом подбираются соответствующие типы автоматов.
Однополюсный
Вводный выключатель с одним полюсом применяется в электросети с одной фазой. Устройство подключается к питанию через клемму (1) сверху, а нижняя клемма (2) соединяется с отходящим проводом (рис. ниже).
Схема однополюсного автомата
Автомат с одним полюсом устанавливается в разрыв фазного провода и отключает его от нагрузки при возникновении аварийной ситуации (рис. ниже). По принципу действия он ничем не отличается от автоматов, установленных на отводящих линиях, но его номинал по току выше (40 А).
Схема вводного однополюсного автомата
Питающая фаза красного цвета подключается к нему, а затем – к счетчику, после чего распределяется на групповые автоматы. Нейтральный провод синего цвета проходит сразу на счетчик, а с него на шину N, затем подключается к каждой линии.
Автомат ввода, установленный перед счетчиком, должен быть опломбирован.
Вводной автомат защищает кабель ввода от перегрева. Если КЗ произойдет на одной из линий ответвлений от него, сработает ее автомат, а другая линия останется работоспособной. Подобная схема подключения позволяет быстро найти и устранить неисправность во внутренней сети.
Двухполюсный
Двухполюсник представляет собой блок с двумя полюсами. Они снабжены объединенным рычажком и имеют общую блокировку между механизмами отключения. Эта конструктивная особенность важна, так как ПУЭ запрещают производить разрыв нулевого провода.
Не допускается установка двух однополюсников вместо одного двухполюсника.
Вводной автомат с двумя полюсами применяется при однофазном вводе из-за особенностей схем подключения в домах старой постройки. В квартиру делается ответвление от стояка межэтажного электрощита однофазной двухпроводной линией. Жэковский электрик может случайно поменять местами провода, ведущие в квартиру. При этом нейтраль окажется на вводном однофазном автомате, а фаза – на нулевых шинах.
Чтобы обеспечить полную гарантию отключения, надо обесточить квартирный щиток с помощью двухполюсника. Кроме того, часто приходится менять пакетный выключатель в этажном щите. Здесь удобнее сразу поставить вместо него двухполюсный вводной автомат.
В квартиру нового дома идет сеть с фазой, нейтралью и заземлением со стандартной цветовой маркировкой. Здесь также не исключена возможность перепутывания проводов из-за низкой квалификации электрика или просто ошибки.
Еще одной причиной установки двухполюсника является замена пробок. На старых квартирных щитках еще остались пробки, которые установлены на фазе и на нуле.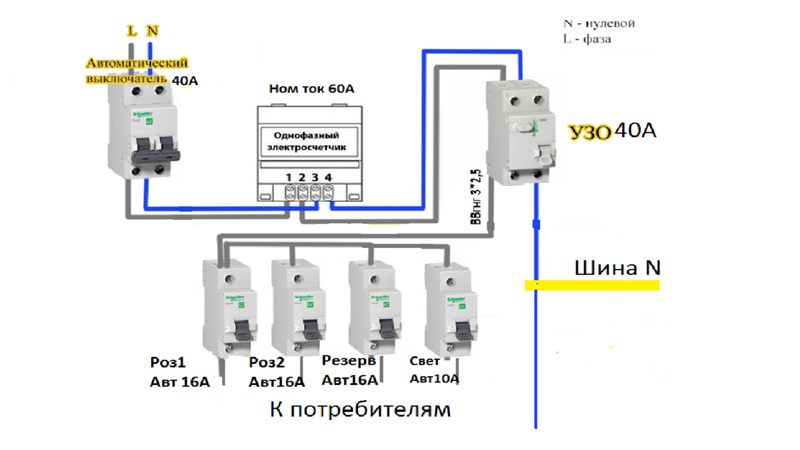 Схема соединений при этом остается прежней.
Схема соединений при этом остается прежней.
ПУЭ запрещают установку предохранителей в нулевых рабочих проводах.
Двухполюсник в данной ситуации установить удобнее, поскольку нет необходимости переделывать схему.
При подключении электричества к частному дому по схеме ТТ двухполюсник необходим, так как в такой системе возможно появления разности потенциалов между нейтральным и заземляющим проводом.
На рис. ниже изображена схема подключения электричества в квартиру с однофазным вводом через двухполюсный автомат.
Схема ввода с двухполюсным автоматом
Питающая фаза подается на него, а затем – на счетчик и на устройство противопожарного защитного заземления УЗО, после чего распределяется на групповые автоматы. Нейтральный провод проходит сразу на счетчик, с него на УЗО, шину N, а затем подключается к УЗО каждой линии. Нулевой проводник заземления зеленого цвета подключается сразу к шине PE, а с нее подходит к заземляющим контактам розеток №1 и №2.
Вводной автоматический выключатель защищает кабель ввода от перегрева и КЗ. Он также может сработать при КЗ на отдельной линии, если там неисправен другой автомат. Номиналы счетчика и противопожарного УЗО подбираются выше (50 А). В этом случае устройства будут также защищены вводным автоматом от перегрузок.
Он также может сработать при КЗ на отдельной линии, если там неисправен другой автомат. Номиналы счетчика и противопожарного УЗО подбираются выше (50 А). В этом случае устройства будут также защищены вводным автоматом от перегрузок.
Трехполюсный
Устройство применяется для трехфазной сети, чтобы обеспечить одновременное отключение всех фаз при перегрузке или коротком замыкании внутренней сети.
К каждой клемме трехполюсника подключается по фазе. На рис. ниже изображены его внешний вид и схема, где для каждого контура существуют отдельные тепловой и электромагнитный расцепители, а также дугогасительная камера.
Трехполюсный автомат в шкафу и его схема
При подключении к частному дому вводной автоматический выключатель устанавливается перед электросчетчиком с защитой на 63 А (рис. ниже). После счетчика ставится УЗО на ток утечки 300 мА. Это связано с большой протяженностью электропроводки дома, где имеет место высокий фон утечки.
После УЗО осуществляется разделение линий от распределительных шин (2) и (4) к розеткам, освещению, а также отдельным группам (6) подачи напряжения в пристройки, трехфазным нагрузкам и другим мощным потребителям.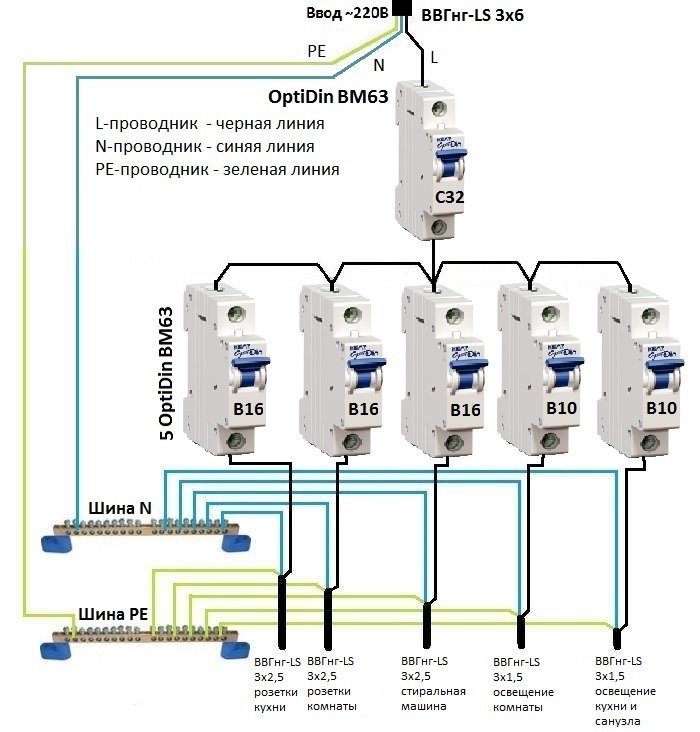
Трехфазная сеть частного дома
Расчет автомата ввода
Независимо от того, является автомат вводным или нет, его рассчитывают путем суммирования токов отходящих к нагрузкам линий. Для этого определяется мощность всех подключаемых потребителей. Номинал определяется для одновременного включения всех потребителей электроэнергии. По этому максимальному току подбирается ближайший номинал автомата из стандартного ряда в сторону уменьшения.
Мощность вводного автомата зависит от номинального тока. При трехфазном питании мощность определяется тем, как подключены нагрузки.
Требуется также определить количество аппаратов коммутации. На ввод требуется только один выключатель, а затем по одному на каждую линию.
На мощные приборы типа электрокотла, водонагревателя, духового шкафа необходимо установить отдельные автоматы. В щитке должно быть предусмотрено место для установки дополнительных автоматических выключателей.
Выбор ВА
Выбор устройства производится по нескольким параметрам:
- Номинальный ток. Его превышение приведет к срабатыванию автомата от перегрузки. Подборка номинального тока производится по сечению подключенной проводки. Для нее определяют допустимый максимальный ток, а затем выбирают номинальный для автомата, предварительно уменьшив его на 10-15%, приводя к стандартному ряду в сторону уменьшения.
- Максимальный ток КЗ. Автомат выбирается по ПКС, которая должна быть равна ему или превышать. Если максимальный ток КЗ составляет 4500 А, подбирается автомат на 4,5 кА. Класс коммутации подбирается для освещения – В (Iпуск>Iном в 3-5 раз), для мощных нагрузок типа отопительного котла – С (Iпуск>Iном в 5-10 раз), для трехфазного двигателя большого станка или сварочного аппарата – D (Iпуск>Iном в 10-12 раз). Тогда защита будет надежной, без ложных срабатываний.
- Установленная мощность.
- Режим нейтрали – тип заземления. В большинстве случаев он представляет собой систему TN с разными вариантами (TN-C, TN-C-S, TN-S),
- Величина линейного напряжения.
- Частота тока.
- Селективность. Номиналы автоматов подбираются по распределению нагрузок в линиях, например, автомат ввода – 40 А, электроплита – 32 А, другие мощные нагрузки – 25 А, освещение – 10 А, розетки – 10 А.
- Схема питания. Автомат подбирается по количеству фаз: одно,- или двухполюсный для однофазной сети, трех,- или четырехполюсный для трехфазной.
- Изготовитель. С целью повышения степени безопасности, автомат выбирается у известных производителей и в специализированных магазинах.
 Его превышение приведет к срабатыванию автомата от перегрузки. Подборка номинального тока производится по сечению подключенной проводки. Для нее определяют допустимый максимальный ток, а затем выбирают номинальный для автомата, предварительно уменьшив его на 10-15%, приводя к стандартному ряду в сторону уменьшения.
Его превышение приведет к срабатыванию автомата от перегрузки. Подборка номинального тока производится по сечению подключенной проводки. Для нее определяют допустимый максимальный ток, а затем выбирают номинальный для автомата, предварительно уменьшив его на 10-15%, приводя к стандартному ряду в сторону уменьшения.
Количество полюсов для трехфазной сети равно четырем. При наличии только трехфазных нагрузок со схемой подключения треугольником, можно использовать трехполюсный автомат.
Выключатель на вводе должен отключать фазы и рабочий ноль, так как в случае утечки на одной из фаз на ноль существует вероятность удара током.
Трехполюсный автомат можно применять для однофазной сети: фаза и ноль подключаются к двум клеммам, а третья останется свободной.
Выбор вводного автомата в зависимости от типа заземления:
- Система TN-S: подводящие нулевые защитный и рабочий провода разделены от подстанции до потребителя (рис. а ниже). Чтобы одновременно отключить фазы и ноль применяются двухполюсные или четырехполюсные вводные автоматы (в зависимости от количества фаз на вводе). Если они с одним или тремя полюсами, нейтраль проводится отдельно от автоматов.
- Система TN-С: подводящие нулевые защитный и рабочий провода совмещены и проходят до потребителя через общий проводник (рис. б). Автомат устанавливается однополюсный или трехполюсный на фазные проводники, а ноль вводится через счетчик на шину N.
 а ниже). Чтобы одновременно отключить фазы и ноль применяются двухполюсные или четырехполюсные вводные автоматы (в зависимости от количества фаз на вводе). Если они с одним или тремя полюсами, нейтраль проводится отдельно от автоматов.
а ниже). Чтобы одновременно отключить фазы и ноль применяются двухполюсные или четырехполюсные вводные автоматы (в зависимости от количества фаз на вводе). Если они с одним или тремя полюсами, нейтраль проводится отдельно от автоматов.Схемы распространенных типов заземлений
Установка
Автомат ввода устанавливается в щитке сверху, с левой стороны. Отводящие линии удобно монтировать сверху вниз. При малом количестве нагрузок он может быть однополюсным и подключаться через фазный провод. В таком случае полного разрыва питающей цепи не происходит.
Монтаж обычно производится на DIN-рейку, при отключении питания.
Видео про электрощит
Ответ на вопрос, как скоммутировать вводной электрощит, можно получить из видео ниже.
Как показывает практика, подключение вводного автомата не является сложной работой. Важно правильно рассчитать его по мощности, продумать схему соединений и установить с учетом особенностей, приведенных в статье.
Оцените статью:Как выбрать автоматический выключатель для дома: по мощности, по току
Если у вас часто срабатывает автоматический выключатель на 16-20 А и обесточивает квартиру, не верьте тем, кто говорит, что нужно просто поставить автомат номиналом побольше. Новый автомат реагировать на перегрузки перестанет, но начнут гореть розетки.
Зачем менять автомат?
Любой электрик скажет: «При наличии отсутствия острой необходимости лучше в электропроводку дома своими руками не лезть». Последствия могут быть печальными. Когда же возникает такая необходимость?
Последствия могут быть печальными. Когда же возникает такая необходимость?
Для того чтобы поменять розетку, нужно знать физику за 8-9 классы. С прочей электрической начинкой все немного сложнее. Если в квартире регулярно срабатывает автомат (автоматический выключатель в щитке) и пропадает свет, пора его менять.
Вероятно, автоматический выключатель выработал свой ресурс, даже несмотря на то, что срок, указанный в паспорте, еще не истек. Изношенный аппарат на 16 А может срабатывать при слабой нагрузке на сеть (10 А), а может не срабатывать при экстремальных значениях (произойдет спаивание контактов, дальше – пожар).
Напомним на всякий случай некоторые сведения из школьной программы:
- Мощность = Напряжение х Ток.
- Ток = Мощность \ Напряжение.
Напряжение в розетке — 220 В. На кофеварке указано 1200 Вт, значит, потребляемый ток будет 1200\220=5,45 (А).
Если вам удалось сложить мощность всех домашних электроприборов и рассчитать общую силу тока, можете считать себя электриком второго уровня.
Как работает автомат и от чего он защищает
Внешне автоматический выключатель представляет собой пластиковый коробок с клеммами для подсоединения проводки, плюс тумблер. Лезть внутрь не обязательно. Для нас важно, что в нем установлены контакты, тепловой и электромагнитный расцепители, которые отвечают за обесточивание сети при повышенной и экстремальной нагрузке.
Как расшифровать маркировку на автоматическом выключателе:
- Буква (A, B, C, D) – это класс автомата, она означает предел тока мгновенного срабатывания, то есть напряжения, когда автомат сразу же обесточивает сеть в квартире. В большинстве случаев в жилых домах будет стоять автомат с буквой C. Он будет моментально срабатывать при 5-10 кратном увеличении силы тока от номинала. То есть автомат с номиналом 10 А вырубит сеть без задержки при значении силы тока 50-100 А. Автомат с B-характеристикой (3-5 кратное превышение) тоже самое сделает при значении 30-50 А.
- Цифра указывает на номинальный ток, то есть значение, до которого автомат будет работать в штатном режиме, ничего не выключая. Тот же автомат на 10 А при превышении силы тока до 11,5 сработает лишь через два часа. При 14,5 подождет минуту, если перенапряжение сети не исчезнет, обесточит квартиру. И так далее, до пиковых значений, обозначенных буквой, когда сеть упадет без задержки.
- Рядом меньшим шрифтом будет стоять другая цифра (в тысячах ампер), обозначающая максимальное значение силы тока, при котором автомат сработает, не получив повреждений.
В чем здесь фокус, почему нельзя сразу отключить сеть, если превышено номинальное значение? Автомат учитывает кратковременные токи, возникающие в сети на доли секунды при включении электрооборудования. Когда вы включаете стиральную машину, пусковой ток может быть выше номинального в 2-3 раза.
Основная функция автоматического выключателя – защищать сеть от короткого замыкания и перегрузки. Когда по линии течет слишком большой ток, проводка нагревается. Если это происходит слишком долго – провод может загореться.
Автомату по большому счету все равно на ваши электроприборы, он их, вопреки расхожему мнению, не защищает от скачков напряжения. Но потерять микроволновку или чайник, подключенные к розетке, это одно, а перегоревшая проводка в стене или в люстре – другое.
Важно понимать, что и от удара током человека при случайном касании токоведущих участков и заземленных предметов автомат тоже не убережет. Для этого существуют устройства защитного отключения (УЗО). Советуют ставить одно общее после вводного автомата и на группы, где есть риск поражения током.
Как выбрать автомат для электропроводки
Для того чтобы правильно выбрать автоматический выключатель, нужно прикинуть максимально допустимую токовую нагрузку сети (суммировать все приборы). Номинал автомата (цифра после буквы) не должен превышать этого значения.
Для обычной квартиры, где нет «серьезных» потребителей питания типа кондиционера, водонагревателя, подойдет автомат класса B. Такая сеть считается слабонагруженной. Ставить высоконагруженный автомат (класса D) для сети, которая питает лампочки опасно. Он не будет воспринимать скачки напряжения в ней как вредные и может пропустить даже короткое замыкание.
Слабонагруженный прибор в сети с большой нагрузкой в штатном режиме наоборот, будет срабатывать не по делу и часто.
Да, чуть не пропустили: автоматы различаются по количеству фаз (полюсов). Число полюсов автомата указывает, с каким из типов сетей он может работать.В квартиру можно также поставить один входной выключатель класса C и по одному однофазному для обеспечения отдельных участков (кухня, комната, отдельно на кондиционер, если предусмотрен). Если нет желания все усложнять, в двухкомнатной квартире можно вполне обойтись одним автоматическим выключателем B с номиналом 16.
Мы почти разобрались, как выбрать автоматический выключатель по току и мощности. Но, если учесть только нагрузку потребителей, можно нарваться на неприятности. Выбор автомата напрямую зависит от типа проводки, кабеля. На слабой проводке мощный автомат при перегрузках не справится со своими задачами. То есть всегда нужно принимать во внимание сечение провода и его пропускную способность.
В домах до 2001-2003 годов с большой долей вероятности будет алюминиевая проводка в однослойной изоляции. Скорее всего, она свое уже отслужила (номинально она может выдержать 20 лет при идеальных условиях, без перегрузок). Ставить на нее новый автомат, учитывая лишь суммарную мощность потребителей, категорически не рекомендуется. Автомат часто срабатывать перестанет, а проблема перегрева останется.
Варианта, по сути, два:
- Менять проводку на медную.
- К мощным потребителям (стиральная машина, бойлер, кондиционер) провести отдельную линию от щитка и поставить на нее отдельный автомат.
Медный провод пропускает больший ток, чем алюминиевый. Но и здесь важно, кроме материала, учитывать его сечение. Оно дает понять, сколько ампер можно пропустить через кабель, не опасаясь повреждения и перегрева.
Для примера:
- Алюминиевый провод сечением 2,5 мм2 безопасно работает с токами до 16-24 А.
- Медный провод сечением 2,5 мм2 безопасно работает с токами 21-30 А.
Это означает, что при нагрузке в 23 А, автомат с номиналом 16 А обесточит проводку через минуту. Вполне достаточно, чтобы медный провод не перегрелся. Если поставить автомат 25 А, до отключения кабель будет пропускать ток за пределами своей нормальной нагрузки, он перегреется, изоляция быстрее износится, розетка со временем перегорит. Для алюминиевой проводки, соответственно, эти значения ниже.
Для простоты понимания предлагаем таблицу выбора автоматического выключателя, исходя из сечения кабеля.
Последний совет: на своей безопасности не следует экономить. Лучше брать автоматы в специализированных магазинах, выбирать производителей с проверенной репутацией. Менеджеры на месте ответят на вопросы, которые мы могли упустить в этой статье.
Какой вводный автомат ставить в квартиру и какой мощности
Вводной автомат (ВА) – устройство защиты электропроводки от таких проблем как замыкание и перегрузка, обеспечивающее общее отключение электричества. Если ВА не установлен, может возникнуть пожар или выход проводников из строя. Автомат защиты имеет электромагнитный и тепловой расцепитель.
Вводной автомат в квартиру: какой выбрать
Различают 3 вида ВА:
- однополюсный;
- двухполюсный;
- трехполюсный;
- четырехполюсный.
Рассмотрим каждый по порядку.
Однополюсный. Данное устройство используется в сетях с одной фазой. Он устанавливается в разрыв провода с фазой и в случае аварии отключает его от нагрузки.
Двухполюсной. У прибора имеется два полюса, которые снабжены общим рычажком и блокировкой отключения. Данная особенность важна по причине того, что ПУЭ запрещает производить разрыв провода с нулем. Стоить помнить, что 2 однополюсника не заменяют двухполюсника. Такой монтаж запрещен. ВА применяется в однофазной сети (квартиры, дома старой постройки). Двухполюсный вводной автомат является обязательным в частных домах, потому что возможна разность потенциалов между нулевым и заземляющим проводом. Такой ВА является наиболее приемлемым вариантом. Теперь вы знаете, какой вводный автомат ставить в квартиру или в частный дом.
Трехполюсный. Данный аппарат применяется в трехфазных сетях. К каждой клемме подключается по фазе. Может устанавливаться в частных домах перед электросчетчиком с 63А защитой. Затем после счетчика монтируется УЗО на 300 мА. Такое устройство необходимо по причине существенной протяженности электропроводки в доме, где вероятна высокая утечка тока.
Четырёхполюсный. Устройство обладает максимальным числом клемм 4*4. Его главное предназначение лежит в защите 3-х фазных электросетей. ВА позволяет реализовать больше схем подключения, чем остальные автоматы.
Определяем какой ВА необходим (мощность, тип заземления)
Аппараты различают по 2-м основным типам заземления.
- TN-C — подводящие нулевые рабочие и защитные провода совмещаются и тянутся к потребителю через общий проводник. Такой тип заземления наблюдается у однополюсных и трехполюсных ВА, которые устанавливаются на фазу, а нулевой ставится на шину N через счетчик.
- TN-S – подводящие нулевые рабочие и защитные проводники разделены от подстанции до потребителя. В зависимости от числа фаз на вводе применяются 2-х и 4-х полюсные ВА. В случае одно- и трехполюсных вводных автоматов, нейтральный провод тянется отдельно.
Итак, какой мощности ставить вводной автомат в квартире? Мощность ВА определяется исходя из учета потребления электроприборов в квартире вместе взятых, а также оптимальную пропускную способность проводки. В квартирах советской постройки с газовой плитой допускается нагрузка до 4 кВт, с электроплитой – до 10-13 кВт. Более точно узнавайте в обслуживающем вас ЖЭКе. Кстати, вводной автомат по доступной цене вы можете приобрести в нашем Интернет-магазине.
Как подобрать автоматический выключатель в дом или квартиру
← Модульные переключатели ввода резерва I-O-II до 125А от Hager || Обеспечение непрерывного электроснабжения коттеджей – ручной и автоматический ввод резервного питания на оборудовании HAGER →
Как подобрать автоматический выключатель в дом или квартиру
Автоматический выключатель или, как часто говорят, автомат – приборы, необходимые для защиты от короткого замыкания или перегрузки любой сети, и конечно же в быту.
Так что самое главное в защите электричества вашего дома, это автоматы. Задача автоматов выключить подачу электрического тока в квартиру при кротком замыкании и перегрузке электросети (см. рис.1). Если такое происходит, необходимо открыть дверь электрощитка, где установлены автоматы и найти тот, у которого рычажок смотрит вниз, как на рисунке, и взвести его вверх. Если автоматический выключатель вновь отключится, можно попробовать достать из розеток вилки тех бытовых приборов (например, электроплита, стиральная или моющая машина, утюг и т.д.), которые защищены этим автоматом. Затем вновь взвести рычажок автомата, и, если он не отключится, пробовать по очереди включать в розетки приборы, чтобы установить возможную причину — неисправность бытовой техники, которая инициирует выключение автомата. Если и здесь вы потерпите неудачу, в любом случае вызывайте специалиста.
Рис.1 Вводной двухполюсный автоматический выключатель производства Hager на 63А.
Наиболее часто встречающиеся неисправности: серьезная поломка бытовой техники, плохой контакт или короткое замыкание в проводах и выход из строя самого автоматического выключателя. Ремонт – задача профессионалов, однако последнюю причину вы можете избегнуть изначально установив автоматический выключатель хорошего производителя. Затраты будут не на много больше, зато на много больше будет уверенности в завтрашнем дне.
Автоматические выключатели делятся по мощности срабатывания в амперах. Бывают основные и часто используемые в квартирах по шкале номинальных токов: 10 А, 16 А, 25 А, 32 А, 40А, а в последнее время 50А и 63 А. Но есть одно НО. Для того чтобы автоматические выключатели работали эффективно, необходимо правильно подобрать их мощность для соответствующей линии. Лучше всего проконсультироваться со специалистами, но если под рукой их нет, сделаем это сами.
Посчитаем потребляемую мощность электроприборов в квартире.
Пример: у вас стоит электроплита с потребляемой мощностью по паспорту 5 кВт (5000 ватт), микроволновка 1 кВт, электрочайник 1.5 кВт. То есть общая мощность, максимально составит суммарно 7.5 кВт. Теперь давайте переведем полученную мощность в амперы, для этого нам нужна знать сколько в одном киловатте ампер.
1 кВ = 4.5 А
Значит если максимальная мощность 7.5 кВ умножаем на 4.5 А и получаем 33.75 А. Берем шкалу номинальных токов автоматов (см. выше): выше 33.75А ближайший номинал 40А. То есть, если нам необходимо поставить защиту на это электрооборудование, требуется автомат на 40 А.
Рис.2 Автоматический выключатель однополюсный 20А.
Но также необходимо принимать во внимание, что этот расчет мы привели из тех условий, что наше оборудование работает постоянно на полную мощность. В жилых помещениях, простых домах и квартирах полная загрузка сети происходит очень редко, ведь вы не пользуетесь той же электроплитой всегда на полную её мощность и одновременно включаете печь, утюг и электрочайник. Так что постарайтесь решить, какие и сколько приборов обычно бывает включено одновременно, в основном это чайник, электробойлер, пылесос, утюг, несколько конфорок на электроплите, телевизор, компьютер.
Современное электрооборудование требует повышенных затрат электроэнергии, Поэтому розетки, свет, прямое подключение разделяют на несколько линий (проводов). Это называется – разделить сеть по нагрузкам. Каждую линию будет контролировать свой автомат, а их всех их уже главный автомат – вводной двухполюсный. См. рис.1 Можно, например, кухню подключить на отдельные автоматы: розетки – 2 линии, посудомоечная машина – 1 линия, электроплита – 1 линия, свет – 1 линия. И т.д. В итоге, получим электро обеспечение со щитком, похожим на этот. См. рис.3. Он сложнее, зато, если правильно будут подписаны автоматы, легко найти «испорченную» линию, а вся остальная квартира останется со светом…
Рис.3 Так выглядит электрический шкаф уже в сборе с автоматическими выключателями.
Выбор автомата по мощности нагрузки и сечению провода
Содержание статьи
Выбор автомата по мощности нагрузки
Для выбора автомата по мощности нагрузки необходимо рассчитать ток нагрузки, и подобрать номинал автоматического выключателя больше или равному полученному значению. Значение тока, выраженное в амперах в однофазной сети 220 В., обычно превышает значение мощности нагрузки, выраженное в киловаттах в 5 раз, т.е. если мощность электроприемника (стиральной машины, лампочки, холодильника) равна 1,2 кВт., то ток, который будет протекать в проводе или кабеле равен 6,0 А(1,2 кВт*5=6,0 А). В расчете на 380 В., в трехфазных сетях, все аналогично, только величина тока превышает мощность нагрузки в 2 раза.
Можно посчитать точнее и посчитать ток по закону ома I=P/U — I=1200 Вт/220В =5,45А. Для трех фаз напряжение будет 380В.
Можно посчитать еще точнее и учесть cos φ — I=P/U*cos φ.
Коэффициент мощности
это безразмерная физическая величина, характеризующая потребителя переменного электрического тока с точки зрения наличия в нагрузке реактивной составляющей. Коэффициент мощности показывает, насколько сдвигается по фазе переменный ток, протекающий через нагрузку, относительно приложенного к ней напряжения.
Численно коэффициент мощности равен косинусу этого фазового сдвига или cos φ
Косинус фи возьмем из таблицы 6.12 нормативного документа СП 31-110-2003 «Проектирование и монтаж электроустановок жилых и общественных зданий»
Таблица 1. Значение Cos φ в зависимости от типа электроприемника
| Тип электроприемника | cos φ |
| Холодильное оборудование предприятий торговли и общественного питания, насосов, вентиляторов и кондиционеров воздуха при мощности электродвигателей, кВт: | |
| до 1 | 0,65 |
| от 1 до 4 | 0,75 |
| свыше 4 | 0,85 |
| Лифты и другое подъемное оборудование | 0,65 |
| Вычислительные машины (без технологического кондиционирования воздуха) | 0,65 |
| Коэффициенты мощности для расчета сетей освещения следует принимать с лампами: | |
| люминесцентными | 0,92 |
| накаливания | 1,0 |
| ДРЛ и ДРИ с компенсированными ПРА | 0,85 |
| то же, с некомпенсированными ПРА | 0,3-0,5 |
| газосветных рекламных установок | 0,35-0,4 |
Примем наш электроприемник мощностью 1,2 кВт. как бытовой однофазный холодильник на 220В, cos φ примем из таблицы 0,75 как двигатель от 1 до 4 кВт.
Рассчитаем ток I=1200 Вт / 220В * 0,75 = 4,09 А.
Теперь самый правильный способ определения тока электроприемника — взять величину тока с шильдика, паспорта или инструкции по эксплуатации. Шильдик с характеристиками есть почти на всех электроприборах.
Автоматические выключатели EKFОбщий ток в линии(к примеру розеточной сети) определяется суммированием тока всех электроприемников. По рассчитанному току выбираем ближайший номинал автоматического автомата в большую сторону. В нашем примере для тока 4,09А это будет автомат на 6А.
ВАЖНО!
Очень важно отметить, что выбирать автоматический выключатель только по мощности нагрузки является грубым нарушением требований пожарной безопасности и может привести к возгоранию изоляции кабеля или провода и как следствие к возникновению пожара. Необходимо при выборе учитывать еще и сечение провода или кабеля.
По мощности нагрузки более правильно выбирать сечение проводника. Требования по выбору изложены в основном нормативном документе для электриков под названием ПУЭ (Правила Устройства Электроустановок), а точнее в главе 1.3. В нашем случае, для домашней электросети, достаточно рассчитать ток нагрузки, как указано выше, и в таблице ниже выбрать сечение проводника, при условии что полученное значение ниже длительно допустимого тока соответствующего его сечению.
Выбор автомата по сечению кабеля
Рассмотрим проблему выбора автоматических выключателей для домашней электропроводки более подробно с учетом требований пожарной безопасности.Необходимые требования изложены главе 3.1 «Защита электрических сетей до 1 кВ.», так как напряжение сети в частных домах, квартирах, дачах равно 220 или 380В.
Расчет сечения жил кабеля и провода
Напряжение 220В.
– однофазная сеть используется в основном для розеток и освещения.
380В. – это в основном сети распределительные – линии электропередач проходящие по улицам, от которых ответвлением подключаются дома.
Согласно требованиям вышеуказанной главы, внутренние сети жилых и общественных зданий должны быть защищены от токов КЗ и перегрузки. Для выполнения этих требований и были изобретены аппараты защиты под названием автоматические выключатели(автоматы).
Автоматический выключатель «автомат»
это механический коммутационный аппарат, способный включать, проводить токи при нормальном состоянии цепи, а также включать, проводить в течение заданного времени и автоматически отключать токи в указанном аномальном состоянии цепи, таких, как токи короткого замыкания и перегрузки.
Короткое замыкание (КЗ)
э- лектрическое соединение двух точек электрической цепи с различными значениями потенциала, не предусмотренное конструкцией устройства и нарушающее его нормальную работу. Короткое замыкание может возникать в результате нарушения изоляции токоведущих элементов или механического соприкосновения неизолированных элементов. Также, коротким замыканием называют состояние, когда сопротивление нагрузки меньше внутреннего сопротивления источника питания.
Ток перегрузки
– превышающий нормированное значение длительно допустимого тока и вызывающий перегрев проводника.Защита от токов КЗ и перегрева необходима для пожарной безопасности, для предотвращения возгорания проводов и кабелей, и как следствие пожара в доме.
Кабели ВВГнг с медными жилами
Длительно допустимый ток кабеля или провода
– величина тока, постоянно протекающего по проводнику, и не вызывающего чрезмерного нагрева.
Величина длительно допустимого тока для проводников разного сечения и материала представлена ниже.Таблица представляет собой совмещенный и упрощенный вариант применимый для бытовых сетей электроснабжения, таблиц № 1.3.6 и 1.3.7 ПУЭ.
| Сечение токо- проводящей жилы, мм | Длительно допустимый ток, А, для проводов и кабелей с медными жилами. | Длительно допустимый ток, А, для проводов и кабелей с алюминиевыми жилами. |
| 1,5 | 19 | — |
| 2,5 | 25 | 19 |
| 4 | 35 | 27 |
| 6 | 42 | 32 |
| 10 | 55 | 42 |
| 16 | 75 | 60 |
| 25 | 95 | 75 |
| 35 | 120 | 90 |
| 50 | 145 | 110 |
Выбор автомата по току короткого замыкания КЗ
Выбор автоматического выключателя для защиты от КЗ (короткого замыкания) осуществляется на основании расчетного значения тока КЗ в конце линии. Расчет относительно сложен, величина зависит от мощности трансформаторной подстанции, сечении проводника и длинны проводника и т.п.
Из опыта проведения расчетов и проектирования электрических сетей, наиболее влияющим параметром является длинна линии, в нашем случае длинна кабеля от щитка до розетки или люстры.
Т.к. в квартирах и частных домах эта длинна минимальна, то такими расчетами обычно пренебрегают и выбирают автоматические выключатели с характеристикой «C», можно конечно использовать «В», но только для освещения внутри квартиры или дома, т.к. такие маломощные светильники не вызывают высокого значения пускового тока, а уже в сети для кухонной техники имеющей электродвигатели, использование автоматов с характеристикой В не рекомендуется, т.к. возможно срабатывание автомата при включении холодильника или блендера из-за скача пускового тока.
Выбор автомата по длительно допустимому току(ДДТ) проводника
Выбор автоматического выключателя для защиты от перегрузки или от перегрева проводника осуществляется на основании величины ДДТ для защищаемого участка провода или кабеля. Номинал автомата должен быть меньше или равен величине ДДТ проводника, указанного в таблице выше. Этим обеспечивается автоматическое отключение автомата при превышении ДДТ в сети, т.е. часть проводки от автомата до последнего электроприемника защищена от перегрева, и как следствие от возникновения пожара.
Провода ПУГНП и ШВВППример выбора автоматического выключателя
Имеем группу от щитка к которой планируется подключить посудомоечную машину -1,6 кВт, кофеварку – 0,6 кВт и электрочайник – 2,0 кВт.
Считаем общую нагрузку и вычисляем ток.
Нагрузка = 0,6+1,6+2,0=4,2 кВт. Ток = 4,2*5=21А.
Смотрим таблицу выше, под рассчитанный нами ток подходят все сечения проводников кроме 1,5мм2 для меди и 1,5 и 2,5 по алюминию.
Выбираем медный кабель с жилами сечением 2,5мм2, т.к. покупать кабель большего сечения по меди не имеет смысла, а алюминиевые проводники не рекомендуются к применению, а может и уже запрещены.
Смотрим шкалу номиналов выпускаемых автоматов — 0.5; 1.6; 2.5; 1; 2; 3; 4; 5; 6; 8; 10; 13; 16; 20; 25; 32; 40; 50; 63.
Автоматический выключатель для нашей сети подойдет на 25А, так как на 16А не подходит потому что рассчитанный ток (21А.) превышает номинал автомата 16А, что вызовет его срабатывание, при включении всех трех электроприемников сразу. Автомат на 32А не подойдет потому что превышает ДДТ выбранного нами кабеля 25А., что может вызвать, перегрев проводника и как следствие пожар.
Сводная таблица для выбора автоматического выключателя для однофазной сети 220 В.
| Номинальный ток автоматического выключателя, А. | Мощность, кВт. | Ток,1 фаза, 220В. | Сечение жил кабеля, мм2. |
| 16 | 0-2,8 | 0-15,0 | 1,5 |
| 25 | 2,9-4,5 | 15,5-24,1 | 2,5 |
| 32 | 4,6-5,8 | 24,6-31,0 | 4 |
| 40 | 5,9-7,3 | 31,6-39,0 | 6 |
| 50 | 7,4-9,1 | 39,6-48,7 | 10 |
| 63 | 9,2-11,4 | 49,2-61,0 | 16 |
| 80 | 11,5-14,6 | 61,5-78,1 | 25 |
| 100 | 14,7-18,0 | 78,6-96,3 | 35 |
| 125 | 18,1-22,5 | 96,8-120,3 | 50 |
| 160 | 22,6-28,5 | 120,9-152,4 | 70 |
| 200 | 28,6-35,1 | 152,9-187,7 | 95 |
| 250 | 36,1-45,1 | 193,0-241,2 | 120 |
| 315 | 46,1-55,1 | 246,5-294,7 | 185 |
Сводная таблица для выбора автоматического выключателя для трехфазной сети 380 В.
| Номинальный ток автоматического выключателя, А. | Мощность, кВт. | Ток, 1 фаза 220В. | Сечение жил кабеля, мм2. |
| 16 | 0-7,9 | 0-15 | 1,5 |
| 25 | 8,3-12,7 | 15,8-24,1 | 2,5 |
| 32 | 13,1-16,3 | 24,9-31,0 | 4 |
| 40 | 16,7-20,3 | 31,8-38,6 | 6 |
| 50 | 20,7-25,5 | 39,4-48,5 | 10 |
| 63 | 25,9-32,3 | 49,2-61,4 | 16 |
| 80 | 32,7-40,3 | 62,2-76,6 | 25 |
| 100 | 40,7-50,3 | 77,4-95,6 | 35 |
| 125 | 50,7-64,7 | 96,4-123,0 | 50 |
| 160 | 65,1-81,1 | 123,8-124,2 | 70 |
| 200 | 81,5-102,7 | 155,0-195,3 | 95 |
| 250 | 103,1-127,9 | 196,0-243,2 | 120 |
| 315 | 128,3-163,1 | 244,0-310,1 | 185 |
| 400 | 163,5-207,1 | 310,9-393,8 | 2х95* |
| 500 | 207,5-259,1 | 394,5-492,7 | 2х120* |
| 630 | 260,1-327,1 | 494,6-622,0 | 2х185* |
| 800 | 328,1-416,1 | 623,9-791,2 | 3х150* |
* — сдвоенный кабель, два кабеля соединенных паралельно, к примеру 2 кабеля ВВГнг 5х120
Итоги
При выборе автомата необходимо учитывать не только мощность нагрузки, но и сечение и материал проводника.
Для сетей с небольшими защищаемыми участками от токов КЗ, можно применять автоматические выключатели с характеристикой «С»
Номинал автомата должен быть меньше или равен длительно допустимому току проводника.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Понравилась статья?
Поделиться с друзьями:
Подпишитесь на новые
Вы знаете, как выбрать правильный алгоритм машинного обучения из 7 различных типов? | Зайд Алисса Алмалики
1-Классифицируйте проблему
Следующим шагом является категоризация проблемы.
Категоризация по входу: Если это помеченные данные, это проблема контролируемого обучения. Если это немаркированные данные с целью поиска структуры, это проблема неконтролируемого обучения. Если решение подразумевает оптимизацию целевой функции путем взаимодействия с окружающей средой, это проблема обучения с подкреплением.
Категоризация по выходу: Если выходом модели является число, это проблема регрессии. Если выходом модели является класс, это проблема классификации. Если выход модели представляет собой набор входных групп, это проблема кластеризации.
2-Поймите свои данные
Данные сами по себе — это не конечная цель, а скорее исходный материал для всего процесса анализа. Успешные компании не только собирают данные и имеют к ним доступ, но и могут получать информацию, которая способствует принятию более эффективных решений, что приводит к более качественному обслуживанию клиентов, конкурентной дифференциации и более высокому росту доходов.Процесс понимания данных играет ключевую роль в процессе выбора правильного алгоритма для правильной задачи. Некоторые алгоритмы могут работать с меньшими наборами образцов, в то время как другие требуют тонны и тонны образцов. Некоторые алгоритмы работают с категориальными данными, в то время как другие предпочитают работать с числовым вводом.
Анализ данных
На этом этапе есть две важные задачи: понимание данных с помощью описательной статистики и понимание данных с помощью визуализации и графиков.
Обработка данных
Компоненты обработки данных включают предварительную обработку, профилирование, очистку, часто также включает сбор данных из различных внутренних систем и внешних источников.
Преобразование данных
Традиционная идея преобразования данных из необработанного состояния в состояние, подходящее для моделирования, заключается в том, где вписывается проектирование признаков. Преобразование данных и проектирование признаков на самом деле могут быть синонимами. А вот определение последнего понятия. Разработка функций — это процесс преобразования необработанных данных в функции, которые лучше представляют основную проблему для прогнозных моделей, что приводит к повышению точности модели для невидимых данных. Автор Джейсон Браунли.
3-Найдите доступные алгоритмы
После классификации проблемы и понимания данных следующей вехой является определение алгоритмов, которые применимы и практичны для реализации в разумные сроки. Некоторые из элементов, влияющих на выбор модели:
- Точность модели.
- Интерпретируемость модели.
- Сложность модели.
- Масштабируемость модели.
- Сколько времени нужно, чтобы построить, обучить и испытать модель?
- Сколько времени нужно, чтобы делать прогнозы с использованием модели?
- Отвечает ли модель бизнес-цели?
4-Реализация алгоритмов машинного обучения.
Настройте конвейер машинного обучения, который сравнивает производительность каждого алгоритма в наборе данных с использованием набора тщательно отобранных критериев оценки.Другой подход — использовать один и тот же алгоритм для разных подгрупп наборов данных. Лучшее решение для этого — сделать это один раз или запустить службу, которая будет делать это через определенные промежутки времени при добавлении новых данных.
5-Оптимизация гиперпараметров. Есть три варианта оптимизации гиперпараметров, поиска по сетке, случайного поиска и байесовской оптимизации.
Типы задач машинного обучения
- Обучение с учителем
- Обучение без учителя
- Обучение с подкреплением
Обучение с учителем
Обучение с учителем так наз. научите алгоритм, к каким выводам он должен прийти.Для контролируемого обучения необходимо, чтобы возможные результаты работы алгоритма были уже известны и чтобы данные, используемые для обучения алгоритма, были помечены правильными ответами. Если на выходе получается действительное число, мы называем задачу регрессией. Если на выходе получается ограниченное количество значений, где эти значения неупорядочены, то это классификация.
Обучение без учителя
Машинное обучение без учителя более тесно связано с тем, что некоторые называют истинным искусственным интеллектом — идеей о том, что компьютер может научиться определять сложные процессы и закономерности без помощи человека, который будет руководить им.Меньше информации об объектах, в частности, поезд без надписи. Можно наблюдать некоторое сходство между группами объектов и включать их в соответствующие кластеры. Некоторые объекты могут сильно отличаться от всех кластеров, таким образом, эти объекты могут быть аномалиями.
Обучение с подкреплением
Обучение с подкреплением относится к целенаправленным алгоритмам, которые учат, как достичь сложной цели или максимизировать в определенном измерении на многих этапах.Например, увеличьте количество очков, набранных в игре за много ходов. Он отличается от контролируемого обучения тем, что при контролируемом обучении данные обучения имеют ролевой ключ, поэтому модель обучается с правильным ответом, тогда как при обучении с подкреплением ответа нет, но агент подкрепления решает, что делать с выполнить поставленную задачу. В отсутствие обучающего набора данных он обязательно извлечет уроки из своего опыта.
Обычно используемые алгоритмы машинного обучения
1-линейная регрессия
Линейная регрессия — это статистический метод, который позволяет суммировать и изучать отношения между двумя непрерывными (количественными) переменными: одна переменная, обозначенная X, рассматривается как независимая переменная.Другая переменная, обозначенная y, считается зависимой переменной. Линейная регрессия использует одну независимую переменную X для объяснения или прогнозирования результата зависимой переменной y, в то время как множественная регрессия использует две или более независимых переменных для прогнозирования результата в соответствии с функцией потерь, такой как среднеквадратичная ошибка (MSE) или средняя абсолютная ошибка ( МАЭ). Итак, всякий раз, когда вам предлагается предсказать какое-то будущее значение процесса, который в настоящее время выполняется, вы можете использовать алгоритм регрессии .Несмотря на простоту этого алгоритма, он довольно хорошо работает, когда есть тысячи функций, например, набор слов или n-граммы при обработке естественного языка. Более сложные алгоритмы страдают от переобучения многих функций и небольших наборов данных, в то время как линейная регрессия обеспечивает достойное качество. Однако это нестабильно, если функции избыточны.
2-Логистическая регрессия
Не путайте эти алгоритмы классификации с методами регрессии для использования регрессии в названии.Логистическая регрессия выполняет двоичную классификацию, поэтому выходные данные меток являются двоичными. Мы также можем рассматривать логистическую регрессию как частный случай линейной регрессии, когда выходная переменная является категориальной, где мы используем логарифм шансов в качестве зависимой переменной. Что особенного в логистической регрессии? Он принимает линейную комбинацию функций и применяет к ней нелинейную функцию (сигмоид), так что это крошечный экземпляр нейронной сети!
3-К-средние
Допустим, у вас есть много точек данных (измерения фруктов), и вы хотите разделить их на две группы: яблоки и груши. K-means clustering — это алгоритм кластеризации, используемый для автоматического разделения большой группы на более мелкие группы.
Название появилось потому, что вы выбрали K групп в нашем примере K = 2. Вы берете среднее значение этих групп, чтобы повысить точность группы (среднее значение равно среднему, и вы делаете это несколько раз). Кластер — это просто еще одно название группы.
Допустим, у вас есть 13 точек данных, которые на самом деле представляют собой семь яблок и шесть груш (но вы этого не знаете), и вы хотите разделить их на две группы.В этом примере предположим, что все груши больше всех яблок. Вы выбираете две случайные точки данных в качестве начальной позиции. Затем вы сравниваете эти точки со всеми другими точками и выясняете, какая стартовая позиция ближе всего. Это ваш первый проход при кластеризации, и это самая медленная часть.
У вас есть начальные группы, но из-за того, что вы выбрали случайный выбор, вы, вероятно, неточны. Допустим, у вас шесть яблок и одна груша в одной группе и два яблока и четыре груши в другой.Итак, вы берете среднее значение всех точек в одной группе для использования в качестве новой отправной точки для этой группы и делаете то же самое для другой группы. Затем вы снова выполняете кластеризацию, чтобы получить новые группы.
Успех! Поскольку среднее значение ближе к большей части каждой группы, при втором обходе вы получаете все яблоки в одной группе и все груши в другой. Как узнать, что все готово? Вы делаете среднее значение, снова выполняете группу и смотрите, изменились ли какие-либо баллы в группах. Ничего подобного, так что вы закончили.В противном случае вы бы пошли еще раз.
4-KNN
Сразу двое стремятся достичь разных целей. K-ближайших соседей — это алгоритм классификации, который является подмножеством контролируемого обучения. K-means — это алгоритм кластеризации, который представляет собой подмножество обучения без учителя.
Если у нас есть набор данных футболистов, их позиций и их измерений, и мы хотим назначить позиции футболистам в новом наборе данных, где у нас есть измерения, но нет позиций, мы можем использовать K-ближайших соседей.
С другой стороны, если у нас есть набор данных футболистов, которых необходимо сгруппировать в K отдельных групп на основе сходства, мы могли бы использовать K-средние. Соответственно, K в каждом случае тоже означает разное!
В K-ближайших соседях, K представляет количество соседей, которые имеют право голоса при определении позиции нового игрока. Посмотрите пример, где K = 5. Если у нас есть новый футболист, которому нужна позиция, мы берем пять футболистов из нашего набора данных с измерениями, наиболее близкими к нашему новому футболисту, и заставляем их проголосовать за позицию, которую мы должны назначить новому игроку.
В K-означает, что K означает количество кластеров, которые мы хотим получить в итоге. Если K = 7, у меня будет семь кластеров или отдельных групп футболистов после запуска алгоритма на моем наборе данных. В конце концов, это два разных алгоритма с двумя очень разными целями, но тот факт, что они оба используют K, может сбивать с толку.
5-опорных векторных машин
SVM использует гиперплоскости (прямые объекты) для разделения двух точек с разными обозначениями (X и O).Иногда точки не могут быть разделены прямыми предметами, поэтому необходимо сопоставить их с пространством более высоких измерений (используя ядра!), Где они могут быть разделены прямыми предметами (гиперплоскостями!). Это выглядит как извилистая линия на исходном пространстве, хотя на самом деле это прямая линия в пространстве гораздо большего измерения!
6-Random Forest
Допустим, мы хотим знать, когда инвестировать в Procter & Gamble, поэтому у нас есть три варианта покупки, продажи и удержания на основе нескольких данных за последний месяц, таких как цена открытия, цена закрытия и т. Д. изменение цены и объема
Представьте, что у вас много записей, 900 точек данных.
Мы хотим построить дерево решений, чтобы выбрать лучшую стратегию, например, если есть изменение в цене акции более чем на десять процентов выше, чем накануне, при большом объеме мы покупаем эту акцию. Но мы не знаем, какие функции использовать, у нас их много.
Итак, мы берем случайный набор мер и случайную выборку нашего обучающего набора и строим дерево решений. Затем мы делаем то же самое много раз, используя разные случайные наборы измерений и каждый раз случайную выборку данных. В конце концов, у нас есть много деревьев решений, мы используем каждое из них для прогнозирования цены, а затем принимаем окончательный прогноз на основе простого большинства.
7-Нейронные сети
Нейронная сеть — это разновидность искусственного интеллекта. Основная идея нейронной сети состоит в том, чтобы моделировать множество плотно связанных между собой клеток мозга внутри компьютера, чтобы он мог учиться, распознавать закономерности и принимать решения по-человечески. Самое удивительное в нейронной сети то, что ей не нужно программировать ее для явного обучения: она обучается сама по себе, как мозг!
С одной стороны нейронной сети есть входы.Это может быть изображение, данные с дрона или состояние доски Go. С другой стороны, есть выходы того, что хочет делать нейронная сеть. Между ними есть узлы и связи между ними. Сила соединений определяет, какой выход требуется на основе входных данных.
Посетите наш бесплатный курс AWS с python на Udemy.
Спасибо за чтение. Если вам понравилась эта статья, не стесняйтесь нажимать кнопку подписки, чтобы мы могли оставаться на связи.
Как выбрать методы подготовки данных для машинного обучения
Последнее обновление 15 июля 2020 г.
Подготовка данных — важная часть проекта прогнозного моделирования.
Правильное применение подготовки данных преобразует необработанные данные в представление, которое позволяет алгоритмам обучения извлекать максимальную пользу из данных и делать умелые прогнозы. Проблема в том, что выбор преобразования или последовательности преобразований, которые приводят к полезному представлению, очень сложен.Настолько, что это можно считать скорее искусством, чем наукой.
В этом руководстве вы познакомитесь со стратегиями, которые можно использовать для выбора методов подготовки данных для наборов данных прогнозного моделирования.
После прохождения этого руководства вы будете знать:
- Методы подготовки данных могут быть выбраны на основе детального знания набора данных и алгоритма, и это наиболее распространенный подход.
- Методы подготовки данных можно искать в сетке как еще один гиперпараметр в конвейере моделирования.
- Преобразования данных могут применяться к обучающему набору данных параллельно для создания множества извлеченных объектов, к которым можно применить выбор признаков и обучить модель.
Начните свой проект с моей новой книги «Подготовка данных для машинного обучения», включая пошаговые руководства и файлы исходного кода Python для всех примеров.
Приступим.
Как выбрать методы подготовки данных для машинного обучения
Фото StockPhotosforFree, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на четыре части; их:
- Стратегии выбора методов подготовки данных
- Подход 1. Определение подготовки данных вручную
- Подход 2: Методы подготовки данных для поиска по сетке
- Подход 3. Параллельное применение методов подготовки данных
Стратегии выбора методов подготовки данных
Модель машинного обучения работает настолько хорошо, насколько хороши данные, используемые для ее обучения.
Это ложится тяжелым бременем на данные и методы, используемые для их подготовки к моделированию.
Подготовка данных — это методы, используемые для преобразования необработанных данных в форму, которая наилучшим образом соответствует ожиданиям или требованиям алгоритма машинного обучения.
Это проблема, потому что мы не можем знать представление необработанных данных, которое приведет к хорошей или наилучшей производительности прогнозной модели.
Однако мы часто не знаем наилучшего повторного представления предикторов для повышения производительности модели.Вместо этого переработка предикторов — это больше искусство, требующее правильных инструментов и опыта для поиска лучших представлений предикторов. Более того, нам может потребоваться поиск множества альтернативных представлений предикторов для повышения производительности модели.
— Стр. Xii, Разработка и выбор функций, 2019.
Вместо этого мы должны использовать контролируемые эксперименты для систематической оценки преобразований данных в модели, чтобы определить, что работает хорошо или лучше всего.
Таким образом, в проекте прогнозного моделирования есть три основных стратегии, которые мы можем решить использовать, чтобы выбрать метод подготовки данных или последовательности методов для набора данных; их:
- Укажите вручную подготовку данных для использования для данного алгоритма на основе глубоких знаний данных и выбранного алгоритма.
- Протестируйте набор различных преобразований данных и последовательности преобразований и выясните, что лучше всего работает в наборе данных для одной или ряда моделей.
- Примените набор преобразований данных к данным параллельно, чтобы создать большое количество инженерных функций, которые можно уменьшить с помощью выбора функций и использовать для обучения моделей.
Давайте подробнее рассмотрим каждый из этих подходов по очереди.
Хотите начать подготовку данных?
Пройдите мой бесплатный 7-дневный ускоренный курс электронной почты (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Загрузите БЕСПЛАТНЫЙ мини-курс
Подход 1. Ручное определение подготовки данных
Этот подход включает изучение данных и требований конкретных алгоритмов, а также выбор преобразований данных, которые изменяют ваши данные в соответствии с требованиями.
Многие практики видят в этом единственно возможный подход к выбору методов подготовки данных, поскольку часто это единственный подход, которому учат или описывают в учебниках.
Этот подход может включать в себя сначала выбор алгоритма и подготовку данных специально для него или тестирование набора алгоритмов и обеспечение того, чтобы методы подготовки данных были адаптированы для каждого алгоритма.
Этот подход требует детального знания ваших данных. Это может быть достигнуто путем просмотра сводной статистики для каждой переменной, графиков распределения данных и, возможно, даже статистических тестов, чтобы увидеть, соответствуют ли данные известному распределению.
Этот подход также требует детального знания алгоритмов, которые вы будете использовать.Этого можно достичь, просмотрев учебники, в которых описаны алгоритмы.
На высоком уровне требования к данным большинства алгоритмов хорошо известны.
Например, следующие алгоритмы, вероятно, будут чувствительны к масштабу и распределению ваших числовых входных переменных, а также к наличию нерелевантных и избыточных переменных:
- Линейная регрессия (и расширения)
- Логистическая регрессия
- Линейный дискриминантный анализ
- Гауссовский Наивный Байес
- Нейронные сети
- Машины опорных векторов
- k-Ближайшие соседи
Следующие алгоритмы, вероятно, не будут чувствительны к масштабу и распределению ваших числовых входных переменных и достаточно нечувствительны к нерелевантным и избыточным переменным:
- Дерево принятия решений
- AdaBoost
- Деревья решений в мешках
- Случайный лес
- Повышение градиента
Преимущество этого подхода в том, что он дает вам некоторую уверенность в том, что ваши данные адаптированы к ожиданиям и требованиям конкретных алгоритмов.Это может привести к хорошей или даже отличной производительности.
Обратной стороной является то, что это может быть медленный процесс, требующий большого анализа, опыта и, возможно, исследований. Это также может привести к ложному чувству уверенности в том, что хорошие или наилучшие результаты уже достигнуты и что дальнейшее улучшение невозможно или невозможно.
Подробнее об этом подходе к подготовке данных см. В руководстве:
Подход 2: Методы подготовки данных для поиска по сетке
Этот подход признает, что алгоритмы могут иметь ожидания и требования, и действительно гарантирует, что преобразования набора данных созданы для удовлетворения этих требований, хотя он не предполагает, что их выполнение приведет к наилучшей производительности.
Это оставляет дверь открытой для неочевидных и неинтуитивных решений.
Это может быть преобразование данных, что « не должно работать, » или « не должно подходить для алгоритма », но приводит к хорошей или отличной производительности. В качестве альтернативы, это может быть отсутствие преобразования данных для входной переменной, которое считается « абсолютно необходимо, », но приводит к хорошей или отличной производительности.
Этого можно достичь, спроектировав поиск по сетке методов подготовки данных и / или последовательности методов подготовки данных в конвейерах.Это может включать оценку каждого по одному выбранному алгоритму машинного обучения или по набору алгоритмов машинного обучения.
Результатом будет большое количество результатов, которые будут четко указывать на те преобразования данных, последовательности преобразований и / или преобразования вместе с моделями, которые приводят к хорошей или лучшей производительности в наборе данных.
Их можно использовать напрямую, хотя более вероятно, что они обеспечат основу для дальнейшего исследования путем настройки преобразований данных и гиперпараметров модели, чтобы получить максимальную отдачу от методов, а абляционные исследования для подтверждения всех элементов конвейера моделирования вносят свой вклад в умелые прогнозы.
Обычно я сам использую этот подход и рекомендую его новичкам или практикам, стремящимся быстро достичь хороших результатов в проекте.
Преимущество этого подхода в том, что он всегда приводит к предложениям по моделированию конвейеров, которые дают хорошие относительные результаты. Что наиболее важно, он может раскрыть неочевидные и неинтуитивные решения для практиков без необходимости глубокого опыта.
Обратной стороной является потребность в некоторой способности программирования для реализации поиска по сетке и дополнительных вычислительных затрат на оценку множества различных методов и конвейеров подготовки данных.
Подробнее об этом подходе к подготовке данных см. В руководстве:
Подход 3: параллельное применение методов подготовки данных
Как и предыдущий подход, этот подход предполагает, что у алгоритмов есть ожидания и требования, а также позволяет находить хорошие решения, которые нарушают эти ожидания, хотя он идет еще дальше.
Этот подход также признает, что модель, подходящая для нескольких точек зрения на одни и те же данные, может быть выгодна по сравнению с моделью, которая соответствует одной точке зрения данных.
Это достигается путем параллельного выполнения нескольких преобразований данных в наборе необработанных данных, а затем сбора результатов всех преобразований вместе в один большой набор данных с сотнями или даже тысячами входных функций (т. Е. Класс FeatureUnion в scikit-learn может использоваться для достижения это). Это позволяет использовать хорошие входные функции, полученные из различных преобразований, параллельно.
Количество входных функций может резко увеличиваться для каждого используемого преобразования. Следовательно, этот подход хорошо комбинировать с методом выбора признаков, чтобы выбрать подмножество признаков, наиболее релевантное целевой переменной.Опять же, это может включать в себя применение одной, двух или более различных методик выбора функций, чтобы обеспечить большее, чем обычно, подмножество полезных функций.
В качестве альтернативы, метод уменьшения размерности (например, PCA) может использоваться для сгенерированных функций, или алгоритм, который выполняет автоматический выбор функций (например, случайный лес), может быть обучен непосредственно на сгенерированных функциях.
Мне нравится думать об этом как о явном подходе к разработке функций, при котором мы генерируем все функции, о которых мы можем думать, из необработанных данных, распаковывая распределения и взаимосвязи в данных.Затем выберите подмножество наиболее подходящих функций и подходящую модель. Поскольку мы явно используем преобразования данных, чтобы распечатать сложность проблемы в параллельных функциях, это может позволить использовать гораздо более простую модель прогнозирования, такую как линейная модель с серьезным штрафом, позволяющим игнорировать менее полезные функции.
Вариантом этого подхода было бы приспособление разных моделей к каждому преобразованию необработанного набора данных и использование ансамблевой модели для объединения прогнозов каждой из моделей.
Преимущество этого общего подхода заключается в том, что он позволяет модели использовать несколько различных точек зрения или представлений на одних и тех же необработанных данных, что отсутствует в двух других подходах, рассмотренных выше. Это может позволить выжать дополнительные навыки прогнозирования из набора данных.
Обратной стороной этого подхода является повышенная стоимость вычислений и тщательный выбор метода выбора функций и / или модели, используемой для интерпретации такого большого количества входных функций.
Подробнее об этом подходе к подготовке данных см. В руководстве:
Дополнительная литература
Этот раздел предоставляет дополнительные ресурсы по теме, если вы хотите углубиться.
Связанные руководства
Книги
Сводка
В этом руководстве вы обнаружили стратегии, которые можно использовать для выбора методов подготовки данных для набора данных прогнозного моделирования.
В частности, вы узнали:
- Методы подготовки данных могут быть выбраны на основе детального знания набора данных и алгоритма, и это наиболее распространенный подход.
- Методы подготовки данных можно искать в сетке как еще один гиперпараметр в конвейере моделирования.
- Преобразования данных могут применяться к обучающему набору данных параллельно для создания множества извлеченных объектов, к которым можно применить выбор признаков и обучить модель.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Получите представление о современной подготовке данных!
Подготовьте данные машинного обучения за считанные минуты
… всего несколькими строками кода Python
Узнайте, как в моей новой электронной книге:
Подготовка данных для машинного обучения
Он предоставляет самоучителей с полным рабочим кодом на:
Выбор функций , RFE , Очистка данных , Преобразования данных , Масштабирование , Уменьшение размерности ,
и многое другое…
Используйте современные методы подготовки данных в
ваших проектах машинного обучения
Посмотрите, что внутри
15-минутное руководство по выбору эффективных курсов машинного обучения и науки о данных
Мотивация
Билл Гейтс провозгласил на недавней церемонии вручения дипломов, что искусственный интеллект (ИИ), энергетика и биология — три самых захватывающих и вознаграждающих выбора карьеры, из которых могут выбирать современные молодые выпускники колледжей.
Не могу с этим согласиться.
Я твердо убежден, что некоторые из наиболее важных вопросов нашего поколения — связанные с устойчивостью, выработкой и распределением энергии, транспортом, доступом к основным жизненным удобствам и т. Д., Зависят от того, насколько разумно мы можем смешать первые два области знаний, о которых упоминает г-н Гейтс.
Другими словами, мир физической электроники (полупроводниковая промышленность составляет центральную часть этого мира) должен делать больше, чтобы полностью охватить плоды информационных технологий и новые разработки в области искусственного интеллекта или науки о данных.
Хотел узнать, но с чего начать?
Я профессионал в области полупроводников с более чем 8-летним опытом работы в ведущей технологической компании после получения докторской степени. Я горжусь тем, что работаю в области физической электроники, которая вносит непосредственный вклад в энергетический сектор. Разрабатываю силовые полупроводниковые приборы. Они созданы для эффективной и надежной передачи электроэнергии, и они питают все, от крошечного датчика внутри вашего смартфона до больших промышленных двигателей, которые перерабатывают пищу или ткань для повседневного потребления.
Поэтому, естественно, я хочу изучить и применить методы современной науки о данных и машинного обучения для улучшения конструкции, надежности и работы таких устройств и систем.
Но я не выпускник информатики. Я не мог отличить связанный список от кучи. Машины опорного вектора звучали как (несколько месяцев назад) какое-то специальное оборудование для людей с ограниченными возможностями. И единственное ключевое слово ИИ, которое я запомнил (из моего факультативного курса на первом курсе), было « исчисление предикатов первого порядка », остаток так называемого « старого AI » или подхода инженерии знаний в противоположность подходу . новый подход, основанный на машинном обучении.
Мне нужно было с чего-то начать изучать основы, а затем углубиться в изучение. Очевидным выбором был MOOC (массовые открытые онлайн-курсы). Я все еще нахожусь в стадии обучения, но считаю, что я, по крайней мере, накопил хороший опыт в выборе правильного MOOC для этого пути. В этой статье я хотел поделиться своими мыслями по этому поводу.
Знай своего «Чи» и своего «врага»
Извините за плохую аналогию 🙂 Это из последней саги о супергероях Netlfix — Защитники.
Но это правда, что вы должны очень хорошо знать свои сильные и слабые стороны и технические склонности, прежде чем начинать процесс обучения через MOOC.
Потому что, давайте посмотрим правде в глаза, время и энергия ограничены, и вы не можете позволить себе тратить свои драгоценные ресурсы на то, что вряд ли будете практиковать на текущей или будущей работе. И это при условии, что вы хотите пройти курс обучения (почти) бесплатно, то есть проводить аудит МООК, а не платить за сертификаты .У меня там есть « почти », потому что в конце этой статьи я хотел бы перечислить несколько MOOC, за которые, как мне кажется, вы должны заплатить, чтобы продемонстрировать сертификаты. И в моем личном путешествии мне пришлось заплатить за несколько курсов Udemy, которые я посетил, потому что они никогда не бывают бесплатными, но вы можете купить их по цене хорошего сэндвича на обед во время проведения акции.
Чему можно и чего нельзя научиться на МООК
На этой картинке я просто хочу показать возможности и невозможности этого процесса i.е. чему вы можете надеяться научиться посредством самообучения и практики, и чему следует научиться на работе, или какой образ мышления необходимо развивать независимо от вашей профессии. При этом, однако, эти круги в целом охватывают основные навыки, которые можно изучить, чтобы заняться наукой о данных / машинным обучением, не имея опыта работы в CS. Обратите внимание, что даже если вы работаете в секторе информационных технологий (ИТ), вам, возможно, предстоит крутой путь обучения, потому что эти новые области разрушают традиционные ИТ, а основные навыки и передовой опыт часто отличаются.
Я, например, считаю сферу науки о данных более демократичной, чем многие другие профессиональные области (например, моя собственная область работы с полупроводниковыми технологиями), где входной барьер невысок, а при достаточной упорной работе и рвении любой может приобрести значимые навыки. Лично у меня нет горячего желания «прорваться» в эту область, скорее, у меня просто есть страсть позаимствовать плоды, чтобы применить их в своей области знаний. Однако эта конечная цель не влияет на начальную кривую обучения, которую нужно пройти.Итак, вы могли бы стать инженером по обработке данных, бизнес-аналитиком, специалистом по машинному обучению или экспертом по визуализации — область и возможности для выбора широко открыты. И если ваша цель такая же, как у меня — оставаться в текущей области знаний и применять недавно изученные методы — у вас тоже все в порядке.
Можно начинать с настоящих основ, ничего страшного 🙂
Я начал с реального базового — изучаю Python на Codeacademy . По всей видимости, вы не можете пойти более элементарно :-).Но это сработало. У меня было отвращение к программированию, но простой и увлекательный интерфейс и правильный темп бесплатного курса Codeacademy были подходящими, чтобы взволновать меня достаточно, чтобы продолжить. Я мог бы выбрать курс Java или C ++ на Coursera, Datacamp или Udacity, но некоторые чтения и исследования показали мне, что Python — оптимальный выбор, уравновешивающий сложность обучения и полезность (особенно для науки о данных), и я решил довериться этой интуиции.
Через некоторое время вы захотите получить более глубокие знания (, но в небольшом темпе)
ВведениеCodeacademy стало хорошей отправной точкой.У меня был выбор из множества онлайн-платформ MOOC, и, как и ожидалось, я записался на несколько курсов одновременно. Однако после нескольких дней занятий на Coursera я понял, что недостаточно готов, чтобы изучать Python у профессора! Я искал курс, преподаваемый каким-то увлеченным инструктором, которому потребуется время, чтобы подробно изучить концепции, научить меня другим важным инструментам, таким как система блокнотов Git и Jupyter, и поддерживать правильный баланс между базовыми концепциями и продвинутыми темами в учебной программе. .И я нашел подходящего человека для этой работы: Хосе Марсиаль Портилья. Он предлагает несколько курсов на Udemy и является одним из самых популярных и получивших положительные отзывы инструкторов на этой платформе. Я зарегистрировался и прошел курс Python Bootcamp . Это было потрясающее введение в язык с правильным темпом, глубиной и строгостью. Я настоятельно рекомендую этот курс для новичков, даже если вам придется выложить 10 долларов (курсы Udemy , как правило, не бесплатны, и их обычная цена составляет 190 или 200 долларов, но вы всегда можете подождать несколько дней, чтобы возобновить цикл промо-акций и зарегистрироваться за 10 долларов. или 15 долларов США).
Важно сосредоточиться на науке о данных
Следующий шаг оказался для меня решающим. Я мог сбиться с пути и попытаться изучить все, что мог, на Python. В частности, объектно-ориентированная часть и часть определения классов, которая легко может затянуть вас в долгом и трудном путешествии. Теперь, не отвлекаясь от этой ключевой области вселенной Python, можно с уверенностью сказать, что вы можете практиковать глубокое обучение и хорошую науку о данных, не имея возможности определять свой собственный класс и методы в Python.Одной из фундаментальных причин постоянно растущей популярности Python как фактического языка, предпочитаемого для науки о данных, является доступность большого количества высококачественных, проверенных экспертами, написанных экспертами библиотек, классов и методов, которые только и ждут загрузки. в красивой упакованной форме и развернутой для бесшовной интеграции в ваш код.
Поэтому для меня было важно быстро перейти к пакетам и методам, наиболее широко используемым в науке о данных — NumPy, Pandas и Matplotlib.
Я познакомился с ними благодаря небольшому изящному курсу от edX. Хотя большинство курсов по edX из университетов и строгих (и длинных ish) по своей природе, есть несколько коротких и более практических / менее теоретических курсов, предлагаемых технологическими компаниями, такими как Microsoft. Одним из них является профессиональная программа Microsoft в области науки о данных . Вы можете зарегистрироваться на любое количество курсов по этой программе. Однако я прошел только следующие курсы (и я намерен вернуться на другие курсы в будущем)
- Ориентация на науку о данных : Обсуждает повседневную жизнь типичного специалиста по данным и затрагивает основные навыки, которые, как ожидается, будут иметь в этой роли, а также базовое введение в составляющие предметы.
- Введение в Python для науки о данных : изучает основы Python — структуры данных, циклы, функции, а затем знакомит с NumPy , Matplotlib и Pandas .
- Введение в анализ данных с использованием Excel : Обучает основным и нескольким расширенным функциям анализа данных, построению графиков и инструментам с Excel (например, сводная таблица , power pivot и подключаемый модуль решателя ).
- Введение в R для науки о данных : знакомит с синтаксисом R, типами данных, векторными и матричными операциями, факторами, функциями, фреймами данных и графикой с помощью ggplot2 .
Хотя эти курсы представляют материал в элементарной форме и охватывают только самые основные примеры, их было достаточно, чтобы зажечь свечу! Боже, меня зацепило!
Перешел на изучение R подробно — с некоторого времени
Последний курс заставил меня осознать несколько важных вещей: (а) статистика и линейная алгебра лежат в основе процесса науки о данных, (б) я недостаточно знал / забыл об этом, и (в) R естественно подходит для та работа, которую я хочу проделать с моим набором данных — данные размером в несколько мегабайт, сгенерированные в результате экспериментов с контролируемым производством полупроводниковых пластин или моделирования TCAD, подготовленные для базового логического анализа.
Это побудило меня искать надежный вводный курс по языку R и к кому лучше обратиться, чем к Хосе Портилья! Я записался на его курс « Data Science and Machine Learning Bootcamp with R ». Это была сделка «купи один — получи еще одну бесплатно», поскольку в первой половине курса были охвачены основы языка R, а затем были переключены на обучение базовым концепциям машинного обучения (все важные концепции, ожидаемые во вводном курсе, были рассмотрены с достаточной тщательностью). В отличие от курса edX Microsoft, в котором использовалась серверная практическая лабораторная среда, этот курс охватывал установку и настройку R Studio и необходимых пакетов, познакомил меня с kaggle и дал необходимый толчок, чтобы перестать быть пассивным учеником (также известным как MOOC video watcher) человеку, который не боится играть с данными.Он также последовал за великой книгой Гарета Джеймса, Даниэлы Виттен, Тревора Хасти и Роберта Тибширани « Введение в статистическое обучение в R » (ISLR), глава за главой.
Если вам разрешено прочитать только одну книгу за всю жизнь для изучения машинного обучения и ничего другого, выберите эту книгу и прочитайте все главы, без исключения. Кстати, в этой книге нет нейронных сетей или материалов по глубокому обучению, так что там…
Вооружившись материалами курса, книгой ISLR и попрактиковавшись на случайных наборах данных, загруженных из kaggle, или даже моих собственных данных об использовании электроэнергии из PG&E, я больше не боялся писать небольшие байты кода, которые действительно могут моделировать что-то интересное или полезное.Я проанализировал некоторые данные о преступности на уровне округов США, выяснил, почему большой план эксперимента может привести к ложной корреляции, и даже об использовании электроэнергии в моей квартире за последние 3 месяца. Я также успешно использовал R для построения прогнозных моделей на основе некоторых реальных наборов данных из моей работы. Статистическая / функциональная природа языка и готовая оценка доверительных интервалов (p-значения или z-оценка) для различных моделей (регрессии или классификации) действительно помогают новому учащемуся легко закрепиться в области статистики. моделирование.
Простое руководство по выбору правильного алгоритма машинного обучения
Йогита Кинха, консультант и блогер .
Что ж, на этот вопрос нет однозначного и однозначного ответа. Ответ зависит от многих факторов, таких как постановка задачи и тип выходных данных, которые вы хотите, тип и размер данных, доступное время вычислений, количество функций и наблюдений в данных, и это лишь некоторые из них.
Вот некоторые важные соображения при выборе алгоритма.
1. Размер обучающих данных
Обычно рекомендуется собрать достаточный объем данных для получения надежных прогнозов. Однако зачастую доступность данных является ограничением. Итак, если обучающие данные меньше или если набор данных имеет меньшее количество наблюдений и большее количество функций, таких как генетика или текстовые данные, выберите алгоритмы с высоким смещением / низкой дисперсией, такие как линейная регрессия, наивный байесовский или линейный SVM.
Если обучающие данные достаточно велики и количество наблюдений больше по сравнению с количеством функций, можно использовать алгоритмы с низким смещением / высокой дисперсией, такие как KNN, деревья решений или ядро SVM.
2. Точность и / или интерпретируемость вывода
Точность модели означает, что функция предсказывает значение отклика для данного наблюдения, которое близко к истинному значению отклика для этого наблюдения. Легко интерпретируемый алгоритм (ограничительные модели, такие как линейная регрессия) означает, что можно легко понять, как каждый отдельный предиктор связан с ответом, в то время как гибкие модели обеспечивают более высокую точность за счет низкой интерпретируемости.
Представление компромисса между точностью и интерпретируемостью с использованием различных методов статистического обучения. ( источник )
Некоторые алгоритмы называются ограничительными, потому что они создают небольшой диапазон форм функции сопоставления. Например, линейная регрессия — это ограничительный подход, потому что он может генерировать только линейные функции, такие как линии.
Некоторые алгоритмы называются гибкими, потому что они могут генерировать более широкий диапазон возможных форм функции отображения.Например, KNN с k = 1 очень гибок, поскольку он будет рассматривать каждую точку входных данных для генерации функции вывода отображения. На рисунке ниже показан компромисс между гибкими и ограничивающими алгоритмами.
Представление компромисса между гибкостью и интерпретируемостью с использованием различных методов статистического обучения. ( источник )
Теперь выбор алгоритма зависит от цели бизнес-задачи.Если целью является вывод, то ограничительные модели лучше, поскольку они гораздо более интерпретируемы. Гибкие модели лучше, если целью является более высокая точность. Как правило, по мере увеличения гибкости метода его интерпретируемость снижается.
3. Скорость или время обучения
Более высокая точность обычно означает большее время обучения. Кроме того, алгоритмам требуется больше времени для обучения на больших обучающих данных. В реальных приложениях выбор алгоритма в основном определяется этими двумя факторами.
Такие алгоритмы, как Наивный Байес, линейная и логистическая регрессия, легко реализовать и быстро запустить. Алгоритмы, такие как SVM, которые включают настройку параметров, нейронные сети с высоким временем сходимости и случайные леса, требуют много времени для обучения данных.
4. Линейность
Многие алгоритмы работают в предположении, что классы могут быть разделены прямой линией (или ее многомерным аналогом). Примеры включают логистическую регрессию и машины опорных векторов.Алгоритмы линейной регрессии предполагают, что тенденции данных следуют прямой линии. Если данные линейны, то эти алгоритмы работают неплохо.
Однако не всегда данные являются линейными, поэтому нам требуются другие алгоритмы, которые могут обрабатывать многомерные и сложные структуры данных. Примеры включают ядро SVM, случайный лес, нейронные сети.
Лучший способ узнать линейность — это подобрать линейную линию или запустить логистическую регрессию или SVM и проверить остаточные ошибки.Более высокая ошибка означает, что данные не являются линейными, и для их согласования потребуются сложные алгоритмы.
5. Количество элементов
Набор данных может иметь большое количество функций, не все из которых актуальны и важны. Для определенного типа данных, например генетических или текстовых, количество функций может быть очень большим по сравнению с количеством точек данных.
Большое количество функций может затруднить работу некоторых алгоритмов обучения, что сделает обучение невероятно длинным.SVM лучше подходит для данных с большим пространством признаков и меньшим количеством наблюдений. Следует использовать методы PCA и выбора функций для уменьшения размерности и выбора важных функций.
Вот удобная шпаргалка , в которой подробно описаны алгоритмы, которые можно использовать для различных типов задач машинного обучения.
источник
Как обсуждалось в моем предыдущем блоге, алгоритмы машинного обученияможно разделить на контролируемое, неконтролируемое и обучение с подкреплением.В этой статье вы узнаете, как пользоваться листом.
Шпаргалка в основном разделена на два типа обучения:
Алгоритмы контролируемого обучения используются там, где обучающие данные имеют выходные переменные, соответствующие входным переменным. Алгоритм анализирует входные данные и изучает функцию для отображения взаимосвязи между входными и выходными переменными.
Обучение с учителем можно разделить на регрессию, классификацию, прогнозирование и обнаружение аномалий.
Неконтролируемое обучение алгоритмы используются, когда данные обучения не имеют переменной ответа. Такие алгоритмы пытаются найти в данных внутренний паттерн и скрытые структуры. Алгоритмы кластеризации и уменьшения размерности — это типы алгоритмов обучения без учителя.
Инфографика ниже просто объясняет регрессию, классификацию, обнаружение аномалий и кластеризацию, а также примеры, где можно применить каждый из них.
источник
Основные моменты, которые следует учитывать при попытке решить новую проблему:
- Определите проблему.Какова цель проблемы?
- Изучите данные и ознакомьтесь с ними.
- Начните с базовых моделей, чтобы построить базовую модель, а затем попробуйте более сложные методы.
Сказав это, всегда помните, что « лучших данных часто лучше лучших алгоритмов », как обсуждалось в моем предыдущем блоге. Не менее важно разработать хорошие функции. Попробуйте несколько алгоритмов и сравните их производительность, чтобы выбрать лучший для вашей конкретной задачи.Кроме того, попробуйте методы ансамбля, поскольку они обычно обеспечивают гораздо лучшую точность.
Оригинал. Размещено с разрешения.
Связанный:
6 лучших курсов машинного обучения
Учебное пособие
Теперь, когда вы ознакомились с рекомендациями курса, вот краткое руководство для вашего пути к машинному обучению. Во-первых, мы коснемся предварительных условий для большинства курсов машинного обучения.
Предварительные требования к курсу
Перед началом более продвинутых курсов потребуются следующие знания:
- Линейная алгебра
- Вероятность
- Исчисление
- Программирование
Это общие компоненты, позволяющие понять, как машинное обучение работает в капюшон.Многие курсы для начинающих обычно требуют хотя бы некоторого программирования и знакомства с основами линейной алгебры, такими как векторы, матрицы и их обозначения.
Первый курс в этом списке, Машинное обучение Эндрю Нг, содержит повторения по большей части математики, которая вам понадобится, но если вы раньше не изучали линейную алгебру, может быть сложно выучить машинное обучение и Линейное Заодно алгебра.
Если вам нужно освежить в памяти необходимую математику, посмотрите:
Я бы порекомендовал изучить Python, поскольку большинство хороших курсов машинного обучения используют Python.Если вы пройдете курс машинного обучения Эндрю Нг, в котором используется Octave, вам следует изучить Python во время курса или после него, поскольку он вам в конечном итоге понадобится. Кроме того, еще один отличный ресурс Python — dataquest.io, у которого есть несколько бесплатных уроков Python в интерактивной среде браузера.
Изучив необходимые предварительные условия, вы можете начать действительно понимать, как работают алгоритмы.
Фундаментальные алгоритмы
Существует базовый набор алгоритмов машинного обучения, с которым каждый должен быть знаком и иметь опыт использования.Это:
- Линейная регрессия
- Логистическая регрессия
- Кластеризация k-средних
- k-ближайших соседей
- Машины опорных векторов (SVM)
- Деревья решений
- Случайные леса
- Наивный Байес
Это предметы первой необходимости, но есть еще много всего. Перечисленные выше курсы содержат, по сути, все это с некоторыми вариациями. Понимание того, как работают эти методы и когда их использовать, будет чрезвычайно важно при принятии новых проектов.
После базовых знаний можно изучить следующие более сложные техники:
- Ансамбли
- Повышение
- Снижение размерности
- Обучение с подкреплением
- Нейронные сети и глубокое обучение
Это только начало, но эти алгоритмы работают. обычно то, что вы видите в самых интересных решениях машинного обучения, и они являются эффективным дополнением к вашему набору инструментов.
И, как и в случае с основными методами, с каждым новым инструментом, который вы изучаете, вы должны взять за привычку сразу же применять его к проекту, чтобы укрепить свое понимание и иметь к чему вернуться, когда вам понадобится освежение знаний.
Реализуйте проект
Обучение машинному обучению онлайн — сложная задача и чрезвычайно полезная. Важно помнить, что простой просмотр видео и прохождение тестов не означает, что вы действительно усваиваете материал. Вы узнаете еще больше, если у вас есть побочный проект, над которым вы работаете, который использует другие данные и преследует другие цели, чем сам курс.
Как только вы начнете изучать основы, вам следует искать интересные данные, к которым вы можете применить эти новые навыки.Вышеупомянутые курсы дадут вам некоторое представление о том, когда применять определенные алгоритмы, поэтому рекомендуется немедленно применять их в собственном проекте.
Путем проб и ошибок, исследований и обратной связи вы узнаете, как экспериментировать с различными методами, как измерять результаты и как классифицировать или делать прогнозы. Чтобы получить представление о том, каким проектом машинного обучения заняться, см. Этот список примеров.
Работа над проектами дает вам лучшее понимание ландшафта машинного обучения на высоком уровне, и по мере того, как вы углубляетесь в более сложные концепции, такие как глубокое обучение, появляется практически неограниченное количество техник и методов, которые нужно понять и с которыми нужно работать.
Прочитать новое исследование
Машинное обучение — быстро развивающаяся область, в которой ежедневно появляются новые методы и приложения. После того, как вы пройдете основы, вы должны быть готовы к работе с некоторыми исследовательскими работами по интересующей вас теме.
Есть несколько веб-сайтов, на которых можно получать уведомления о новых статьях, соответствующих вашим критериям. Google Scholar — это всегда хорошее место для начала. Введите такие ключевые слова, как «машинное обучение» и «твиттер» или что-нибудь еще, что вас интересует, и нажмите небольшую ссылку «Создать оповещение» слева, чтобы получать электронные письма.
Сделайте еженедельной привычкой читать эти предупреждения, просматривать документы, чтобы увидеть, стоит ли их читать, а затем обязаться понять, что происходит. Если это связано с проектом, над которым вы работаете, посмотрите, сможете ли вы применить эти методы к своей собственной проблеме.
Заключение
Машинное обучение невероятно увлекательно и интересно учиться и экспериментировать, и я надеюсь, что вы нашли курс выше, который соответствует вашему собственному путешествию в эту захватывающую область.
Машинное обучение составляет один из компонентов науки о данных, и если вы также заинтересованы в изучении статистики, визуализации, анализа данных и многого другого, обязательно ознакомьтесь с лучшими курсами по науке о данных, которые являются руководством, которое следует за похожий на этот формат.
Наконец, если у вас есть какие-либо вопросы или предложения, не стесняйтесь оставлять их в комментариях ниже.
Спасибо за чтение и получайте удовольствие от обучения!
Учебное пособие по машинному обучению с примерами
Машинное обучение (ML) становится самостоятельным, с растущим признанием того, что машинное обучение может играть ключевую роль в широком спектре критически важных приложений, таких как интеллектуальный анализ данных, обработка естественного языка, изображения распознавание и экспертные системы. Машинное обучение предлагает потенциальные решения во всех этих и других областях и призвано стать опорой нашей будущей цивилизации.
Предложение способных дизайнеров машинного обучения еще не соответствует этому спросу. Основная причина этого в том, что машинное обучение просто непросто. Это руководство по машинному обучению знакомит с основами теории машинного обучения, излагает общие темы и концепции, позволяя легко следовать логике и освоить основы машинного обучения.
Что такое машинное обучение?
Так что же такое «машинное обучение»? ML — это на самом деле партии и вещей.Эта область довольно обширна и быстро расширяется, непрерывно разбиваясь и до тошноты подразделяясь на различные под-специальности и типы машинного обучения.
Тем не менее, есть некоторые основные общие темы, и общая тема лучше всего резюмируется этим часто цитируемым заявлением, сделанным Артуром Самуэлем еще в 1959 году: «[Машинное обучение — это] область исследования, которая дает компьютерам возможность учиться без явного программирования ».
И совсем недавно, в 1997 году, Том Митчелл дал «правильное» определение, которое оказалось более полезным для инженеров: «Считается, что компьютерная программа учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P , если его характеристики по T, измеренные с помощью P, улучшаются с опытом E.”
«Считается, что компьютерная программа учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P, если ее производительность на T, измеренная с помощью P, улучшается с опытом E.» — Том Митчелл, Университет Карнеги-Меллона
Итак, если вы хотите, чтобы ваша программа предсказывала, например, модели трафика на оживленном перекрестке (задача T), вы можете запустить ее с помощью алгоритма машинного обучения с данными о прошлых моделях трафика (опыт E) и, если она успешно « изучено », тогда он будет лучше предсказывать будущие модели трафика (показатель эффективности P).
Однако очень сложная природа многих реальных проблем часто означает, что изобретение специализированных алгоритмов, которые будут идеально их решать каждый раз, непрактично, если не невозможно. Примеры проблем машинного обучения: «Это рак?», «Какова рыночная стоимость этого дома?», «Кто из этих людей дружит друг с другом?», «Взрывается ли этот ракетный двигатель при взлете? »,« Понравится ли этому человеку этот фильм? »,« Кто это? »,« Что ты сказал? »И« Как ты на этой штуке летишь? ».Все эти проблемы — отличные цели для проекта машинного обучения, и фактически машинное обучение применялось к каждой из них с большим успехом.
ML решает проблемы, которые нельзя решить только численными методами.
Среди различных типов задач машинного обучения принципиальное различие проводится между контролируемым и неконтролируемым обучением:
- Машинное обучение с учителем: Программа «обучается» на заранее определенном наборе «обучающих примеров», которые затем облегчают ее способность прийти к точному выводу при получении новых данных.
- Неконтролируемое машинное обучение: Программа получает набор данных и должна находить в них закономерности и взаимосвязи.
Здесь мы в первую очередь сосредоточимся на обучении с учителем, но в конце статьи содержится краткое обсуждение обучения без учителя с некоторыми ссылками для тех, кто заинтересован в дальнейшем изучении темы.
Машинное обучение с учителем
В большинстве приложений контролируемого обучения конечной целью является разработка точно настроенной функции прогнозирования h (x) (иногда называемой «гипотезой»).«Обучение» заключается в использовании сложных математических алгоритмов для оптимизации этой функции так, чтобы с учетом входных данных x о некотором домене (скажем, квадратном метре дома) можно было точно предсказать какое-то интересное значение h (x) ( скажем, рыночная цена на указанный дом).
На практике x почти всегда представляет несколько точек данных. Так, например, предсказатель цен на жилье может учитывать не только квадратные метры ( x1 ), но также количество спален ( x2 ), количество ванных комнат ( x3 ), количество этажей ( x4) , год выпуска ( x5 ), почтовый индекс ( x6 ) и т. д.Определение того, какие входные данные использовать, является важной частью дизайна машинного обучения. Однако для пояснения проще всего предположить, что используется одно входное значение.
Допустим, у нашего простого предиктора есть такая форма:
где и — константы. Наша цель — найти идеальные значения и сделать так, чтобы наш предсказатель работал как можно лучше.
Оптимизация предиктора h (x) выполняется с использованием обучающих примеров . Для каждого обучающего примера у нас есть входное значение x_train , для которого заранее известен соответствующий выход y .Для каждого примера мы находим разницу между известным правильным значением y и нашим прогнозируемым значением h (x_train) . При наличии достаточного количества обучающих примеров эти различия дают нам полезный способ измерить «ошибочность» h (x) . Затем мы можем настроить h (x) , изменив значения и сделав «менее ошибочным». Этот процесс повторяется снова и снова, пока система не найдет наилучшие значения для и. Таким образом, предсказатель обучается и готов делать некоторые прогнозы в реальном мире.
Примеры машинного обучения
В этом посте мы остановимся на простых задачах для иллюстрации, но ML существует потому, что в реальном мире проблемы намного сложнее. На этом плоском экране мы можем нарисовать вам изображение, самое большее, трехмерного набора данных, но проблемы машинного обучения обычно связаны с данными с миллионами измерений и очень сложными функциями прогнозирования. ML решает проблемы, которые нельзя решить только численными методами.
Имея это в виду, давайте рассмотрим простой пример.Допустим, у нас есть следующие данные по обучению, в которых сотрудники компании оценили свою удовлетворенность по шкале от 1 до 100:
Во-первых, обратите внимание на то, что данные немного зашумлены. То есть, хотя мы можем видеть, что в этом есть закономерность (например, удовлетворенность сотрудников имеет тенденцию повышаться по мере роста заработной платы), не все это четко вписывается в прямую линию. Это всегда будет иметь место с реальными данными (и мы абсолютно хотим обучить нашу машину, используя реальные данные!). Так как же тогда научить машину точно предсказывать уровень удовлетворенности сотрудников? Ответ, конечно же, такой, что мы не можем.Цель ML никогда не состоит в том, чтобы делать «идеальные» предположения, потому что ML работает в тех областях, где таких вещей нет. Цель состоит в том, чтобы сделать предположения, которые достаточно хороши, чтобы быть полезными.
Это чем-то напоминает известное утверждение британского математика и профессора статистики Джорджа Э. П. Бокса о том, что «все модели неверны, но некоторые полезны».
Цель ML никогда не состоит в том, чтобы делать «идеальные» предположения, потому что ML работает в тех областях, где таких вещей нет. Цель состоит в том, чтобы сделать предположения, которые достаточно хороши, чтобы быть полезными.
Машинное обучение в значительной степени опирается на статистику. Например, когда мы обучаем нашу машину обучению, мы должны предоставить ей статистически значимую случайную выборку в качестве обучающих данных. Если обучающая выборка не случайна, мы рискуем получить шаблоны машинного обучения, которых на самом деле нет. А если обучающая выборка слишком мала (см. Закон больших чисел), мы не узнаем достаточно и можем даже прийти к неточным выводам. Например, попытка предсказать модели удовлетворенности в масштабах компании на основе только данных высшего руководства, вероятно, будет подвержена ошибкам.
С этим пониманием давайте дадим нашей машине данные, которые мы дали выше, и пусть она их изучит. Сначала мы должны инициализировать наш предсказатель h (x) с некоторыми разумными значениями и. Теперь наш предиктор выглядит так, если поместить его над обучающим набором:
Если мы спросим этот предсказатель для удовлетворенности сотрудника, зарабатывающего 60 тысяч долларов, он даст рейтинг 27:
.Очевидно, что это была ужасная догадка и что эта машина не очень многого знает.
Итак, давайте дадим этому предсказателю все зарплаты из нашего обучающего набора и возьмем разницу между полученными прогнозируемыми оценками удовлетворенности и фактическими оценками удовлетворенности соответствующих сотрудников. Если мы выполним небольшое математическое волшебство (которое я вскоре опишу), мы сможем вычислить с очень высокой степенью уверенности, что значения 13,12 for и 0,61 for дадут нам лучший прогноз.
И если мы повторим этот процесс, скажем 1500 раз, наш предсказатель будет выглядеть так:
На этом этапе, если мы повторим процесс, мы обнаружим это и больше не изменимся на сколько-нибудь заметную величину, и, таким образом, мы увидим, что система слилась.Если мы не совершили ошибок, значит, мы нашли оптимальный предсказатель. Соответственно, если мы теперь снова спросим машину об оценке удовлетворенности сотрудника, который зарабатывает 60 тысяч долларов, он предсказывает оценку примерно 60.
Теперь мы к чему-то приближаемся.
Регрессия машинного обучения: заметка о сложности
Приведенный выше пример технически представляет собой простую задачу одномерной линейной регрессии, которая в действительности может быть решена путем вывода простого нормального уравнения и полного пропуска этого процесса «настройки».Однако рассмотрим предсказатель, который выглядит так:
Эта функция принимает входные данные в четырех измерениях и имеет множество полиномиальных членов. Вывести нормальное уравнение для этой функции — серьезная проблема. Многие современные задачи машинного обучения требуют тысячи или даже миллионов измерений данных для построения прогнозов с использованием сотен коэффициентов. Предсказание того, как будет выражен геном организма или каким будет климат через пятьдесят лет, — вот примеры таких сложных проблем.
Многие современные задачи машинного обучения требуют тысячи или даже миллионов измерений данных для построения прогнозов с использованием сотен коэффициентов.
К счастью, итеративный подход, применяемый в системах машинного обучения, гораздо более устойчив к такой сложности. Вместо того, чтобы использовать грубую силу, система машинного обучения «нащупывает путь» к ответу. Для больших проблем это работает намного лучше. Хотя это не означает, что машинное обучение может решать все сколь угодно сложные проблемы (не может), оно представляет собой невероятно гибкий и мощный инструмент.
Градиентный спуск — минимизация «неправильности»
Давайте подробнее рассмотрим, как работает этот итеративный процесс. В приведенном выше примере, как убедиться, что с каждым шагом становится лучше, а не хуже? Ответ кроется в нашем «измерении ошибочности», о котором говорилось ранее, а также в небольшом исчислении.
Мера ошибочности известна как функция стоимости (также известная как функция потерь ),. Входные данные представляют все коэффициенты, которые мы используем в нашем предсказателе.Так что в нашем случае это действительно пара и. дает нам математическое измерение того, насколько ошибается наш предсказатель, когда он использует данные значения и.
Выбор функции стоимости — еще одна важная часть программы машинного обучения. В разных контекстах «неправота» может означать очень разные вещи. В нашем примере удовлетворенности сотрудников общепринятым стандартом является линейная функция наименьших квадратов:
При использовании метода наименьших квадратов штраф за неправильное предположение увеличивается квадратично с разницей между предположением и правильным ответом, поэтому он действует как очень «строгий» критерий ошибочности.Функция стоимости вычисляет средний штраф по всем обучающим примерам.
Итак, теперь мы видим, что наша цель — найти и для нашего предиктора h (x) такой, чтобы наша функция стоимости была как можно меньше. Мы обращаемся к силе исчисления для достижения этой цели.
Рассмотрим следующий график функции стоимости для некоторой конкретной задачи машинного обучения:
Здесь мы можем увидеть стоимость, связанную с разными значениями и. Мы видим, что график имеет небольшую чашу по форме.Нижняя часть чаши представляет собой наименьшую стоимость, которую наш предсказатель может дать нам на основе заданных данных обучения. Цель состоит в том, чтобы «скатиться с холма» и найти и соответствовать этой точке.
Вот где в этом руководстве по машинному обучению используются вычисления. Чтобы это объяснение было управляемым, я не буду записывать здесь уравнения, но, по сути, мы берем градиент, который представляет собой пару производных от (одна больше и одна больше). Градиент будет разным для каждого значения и и говорит нам, какой «наклон холма» и, в частности, «какой путь вниз» для этих конкретных s.Например, когда мы вставляем наши текущие значения в градиент, он может сказать нам, что добавление небольшого количества и небольшое вычитание приведет нас в направлении нижней границы функции стоимости. Поэтому мы немного прибавляем, немного вычитаем из, и вуаля! Мы завершили один раунд нашего алгоритма обучения. Наш обновленный предсказатель h (x) = + x будет давать более точные прогнозы, чем раньше. Наша машина стала немного умнее.
Этот процесс переключения между вычислением текущего градиента и обновлением s на основе результатов известен как градиентный спуск.
Это охватывает основную теорию, лежащую в основе большинства контролируемых систем машинного обучения. Но основные концепции можно применять по-разному, в зависимости от решаемой проблемы.
Проблемы классификации в машинном обучении
Под контролируемым ML две основные подкатегории:
- Системы машинного обучения с регрессией: Системы, в которых прогнозируемое значение находится где-то в непрерывном спектре.Эти системы помогают нам с вопросами «Сколько?» или «Сколько?».
- Классификация систем машинного обучения: Системы, в которых мы ищем прогноз типа «да» или «нет», например «Является ли этот томер злокачественным?», «Соответствует ли этот файл cookie нашим стандартам качества?» И т. Д.
Как оказалось, лежащая в основе теория машинного обучения более или менее одинакова. Основными отличиями являются конструкция предиктора h (x) и конструкция функции стоимости.
До сих пор наши примеры были сосредоточены на задачах регрессии, поэтому давайте теперь также рассмотрим пример классификации.
Вот результаты исследования качества файлов cookie, где все обучающие примеры были помечены синим цветом как «хорошие cookie» ( y = 1 ) или как «плохие cookie» ( y = 0 ) красным.
В классификации предсказатель регрессии не очень полезен. Обычно нам нужен предсказатель, который делает предположение где-то между 0 и 1. В классификаторе качества файлов cookie прогноз, равный 1, представляет собой очень уверенное предположение о том, что файл cookie является идеальным и совершенно аппетитным.Прогноз, равный 0, означает высокую уверенность в том, что cookie-файлы создают неудобства для индустрии cookie-файлов. Значения, попадающие в этот диапазон, представляют меньшую уверенность, поэтому мы могли бы спроектировать нашу систему таким образом, чтобы прогноз 0,6 означал «Чувак, это сложный вызов, но я соглашусь, да, вы можете продать этот файл cookie», в то время как значение точно в среднее значение 0,5 может представлять полную неопределенность. Это не всегда то, как уверенность распределяется в классификаторе, но это очень распространенный дизайн и работает для целей нашей иллюстрации.
Оказывается, есть хорошая функция, которая хорошо фиксирует это поведение. Это называется сигмовидной функцией, g (z) , и выглядит это примерно так:
z — это некоторое представление наших входных данных и коэффициентов, например:
, чтобы наш предсказатель стал:
Обратите внимание, что сигмоидальная функция преобразует наш вывод в диапазон от 0 до 1.
Логика построения функции затрат также отличается по классификации.Мы снова спрашиваем: «Что значит неправильное предположение?» и на этот раз очень хорошее эмпирическое правило состоит в том, что если правильное предположение было 0, а мы угадали 1, то мы были полностью и совершенно неправы, и наоборот. Поскольку нельзя ошибаться больше, чем абсолютно ошибаться, наказание в этом случае будет огромным. В качестве альтернативы, если правильное предположение было 0, а мы угадали 0, наша функция стоимости не должна добавлять какие-либо затраты каждый раз, когда это происходит. Если предположение было верным, но мы не были полностью уверены (например, y = 1 , но h (x) = 0.8 ), это должно быть связано с небольшими затратами, и, если наше предположение было неверным, но мы не были полностью уверены (например, y = 1 , но h (x) = 0,3 ), это должно иметь значительные затраты. , но не настолько, как если бы мы были полностью неправы.
Это поведение фиксируется функцией журнала, например:
Опять же, функция стоимости дает нам среднюю стоимость по всем нашим обучающим примерам.
Итак, здесь мы описали, чем предиктор h (x) и функция стоимости различаются между регрессией и классификацией, но градиентный спуск по-прежнему работает нормально.
Предиктор классификации можно визуализировать, нарисовав граничную линию; то есть барьер, при котором прогноз изменяется с «да» (прогноз более 0,5) на «нет» (прогноз менее 0,5). Благодаря хорошо спроектированной системе наши данные cookie могут генерировать границу классификации, которая выглядит следующим образом:
Теперь это машина, которая кое-что знает о печенье!
Введение в нейронные сети
Ни одно обсуждение машинного обучения не будет полным без хотя бы упоминания нейронных сетей.Нейронные сети не только предлагают чрезвычайно мощный инструмент для решения очень сложных задач, но также предлагают увлекательные намеки на работу нашего собственного мозга и интригующие возможности для создания действительно интеллектуальных машин в один прекрасный день.
Нейронные сети хорошо подходят для моделей машинного обучения, в которых количество входных данных огромно. Вычислительные затраты на решение такой проблемы слишком велики для типов систем, которые мы обсуждали выше. Однако оказывается, что нейронные сети можно эффективно настроить с помощью методов, которые в принципе поразительно похожи на градиентный спуск.
Подробное обсуждение нейронных сетей выходит за рамки этого руководства, но я рекомендую ознакомиться с нашим предыдущим постом по этой теме.
Машинное обучение без учителя
Неконтролируемое машинное обучение обычно занимается поиском взаимосвязей в данных. В этом процессе не используются обучающие примеры. Вместо этого системе предоставляется набор данных и задача поиска закономерностей и корреляций в них. Хороший пример — определение сплоченных групп друзей в данных социальных сетей.
Используемые для этого алгоритмы машинного обучения сильно отличаются от алгоритмов, используемых для обучения с учителем, и эта тема заслуживает отдельной публикации. Тем не менее, чтобы кое-что обсудить, взгляните на алгоритмы кластеризации, такие как k-среднее, а также на системы уменьшения размерности, такие как анализ основных компонентов. В нашей предыдущей публикации о больших данных некоторые из этих тем также обсуждались более подробно.
Заключение
Здесь мы рассмотрели большую часть базовой теории, лежащей в основе области машинного обучения, но, конечно, мы коснулись лишь поверхности.
Имейте в виду, что для того, чтобы действительно применить теории, содержащиеся в этом введении, к реальным примерам машинного обучения, необходимо гораздо более глубокое понимание обсуждаемых здесь тем. В машинном обучении есть много тонкостей и ловушек, а также множество способов сбиться с пути с помощью того, что кажется идеально настроенной мыслящей машиной. Практически со всеми частями базовой теории можно бесконечно играть и изменять, и результаты часто бывают захватывающими. Многие из них перерастают в совершенно новые области обучения, которые лучше подходят для решения конкретных задач.
Очевидно, что машинное обучение — невероятно мощный инструмент. В ближайшие годы он обещает помочь решить некоторые из наших самых насущных проблем, а также откроет совершенно новые миры возможностей для компаний, занимающихся анализом данных. Спрос на инженеров машинного обучения будет только расти, предлагая невероятные шансы стать частью чего-то большого. Надеюсь, вы подумаете о том, чтобы принять участие в акции!
Благодарность
Эта статья в значительной степени опирается на материал, преподаваемый профессором Стэнфорда доктором Дж.Эндрю Нг в своем бесплатном открытом курсе машинного обучения. Курс подробно описывает все, что обсуждается в этой статье, и дает множество практических советов для практикующих ML. Я не могу рекомендовать этот курс достаточно высоко для тех, кто заинтересован в дальнейшем изучении этой увлекательной области.
Лучшие 34 вопросов и ответов на собеседование по машинному обучению [2021]
Компании стремятся сделать информацию и услуги более доступными для людей, внедряя такие новейшие технологии, как искусственный интеллект (ИИ) и машинное обучение.Можно стать свидетелем растущего внедрения этих технологий в таких промышленных секторах, как банковское дело, финансы, розничная торговля, производство, здравоохранение и т. Д.
Специалисты по обработке данных, инженеры по искусственному интеллекту, инженеры по машинному обучению и аналитики данных — вот некоторые из востребованных организационных ролей, которые используют ИИ. Если вы стремитесь подать заявку на эти типы вакансий, очень важно знать, какие вопросы собеседования с машинным обучением могут задать рекрутеры и менеджеры по найму.
В этой статье вы найдете ответы на некоторые вопросы и ответы на собеседование по машинному обучению, с которыми вы, вероятно, столкнетесь на пути к достижению работы своей мечты.
Программа аспирантуры по искусственному интеллекту и машинному обучению
В партнерстве с Университетом ПердьюПосмотреть курсЛучшие вопросы на собеседовании по машинному обучению
Начнем с некоторых часто задаваемых вопросов и ответов на собеседовании по машинному обучению.
1. Какие существуют типы машинного обучения?
Существует три типа машинного обучения:
Обучение с учителем
В управляемом машинном обучении модель делает прогнозы или решения на основе прошлых или помеченных данных.Помеченные данные относятся к наборам данных, которым присвоены теги или метки, что делает их более значимыми.
Обучение без учителя
При обучении без учителя у нас нет маркированных данных. Модель может определять закономерности, аномалии и взаимосвязи во входных данных.
Обучение с подкреплением
Используя обучение с подкреплением, модель может учиться на основе вознаграждений, полученных за свое предыдущее действие.
Рассмотрим среду, в которой работает агент.Агенту ставится цель, которую нужно достичь. Каждый раз, когда агент предпринимает какие-либо действия по отношению к цели, он получает положительный отзыв. И, если предпринятое действие уходит от цели, агент получает отрицательных отзывов .
2. Что такое переобучение и как его избежать?
Переобучение — это ситуация, которая возникает, когда модель слишком хорошо усваивает обучающий набор, принимая случайные колебания обучающих данных как концепции. Это влияет на способность модели к обобщению и неприменимо к новым данным.
Когда модели предоставляются обучающие данные, она показывает 100-процентную точность — технически небольшую потерю. Но, когда мы используем тестовые данные, возможна ошибка и низкая эффективность. Это состояние известно как переобучение.
Есть несколько способов избежать переобучения, например:
- Регуляризация. Он включает термин стоимости для функций, связанных с целевой функцией .
- Изготовление простой модели. С меньшим количеством переменных и параметров дисперсия может быть уменьшена
- Также можно использовать методы перекрестной проверки, такие как k-складки
- Если некоторые параметры модели могут вызвать переоснащение, можно использовать методы регуляризации, такие как LASSO, которые штрафуют эти параметры
3.Что такое «обучающий набор» и «набор тестов» в модели машинного обучения? Сколько данных вы выделите для своих наборов для обучения, проверки и тестирования?
Для создания модели используется трехэтапный процесс:
- Обучаем модель
- Протестируйте модель
- Разверните модель
| Учебный комплект | Тестовый набор |
|---|---|
|
|
Рассмотрим случай, когда вы пометили данные для 1000 записей.Один из способов обучения модели — открыть в процессе обучения все 1000 записей. Затем вы берете небольшой набор тех же данных для тестирования модели, которая в этом случае даст хорошие результаты.
Но это не точный способ тестирования. Итак, мы отложили часть этих данных, называемую «набором тестов», перед тем, как начать процесс обучения. Остальные данные называются «обучающим набором», который мы используем для обучения модели. Обучающий набор проходит через модель несколько раз, пока точность не станет высокой, а ошибки минимизированы.
Теперь мы передаем тестовые данные, чтобы проверить, может ли модель точно предсказать значения и определить, эффективно ли обучение. Если вы получаете ошибки, вам нужно либо изменить свою модель, либо переобучить ее с дополнительными данными.
Что касается вопроса о том, как разделить данные на обучающий набор и тестовый набор, здесь нет фиксированного правила, и соотношение может варьироваться в зависимости от индивидуальных предпочтений.
4. Как поступать с отсутствующими или поврежденными данными в наборе данных?
Один из самых простых способов справиться с отсутствующими или поврежденными данными — удалить эти строки или столбцы или полностью заменить их каким-либо другим значением.
В Pandas есть два полезных метода:
- IsNull () и dropna () помогут найти столбцы / строки с отсутствующими данными и сбросить их
- Fillna () заменит неправильные значения значением заполнителя
5. Как выбрать классификатор на основе размера данных обучающего набора?
Когда обучающая выборка мала, модель с правильным смещением и низкой дисперсией, кажется, работает лучше, потому что у них меньше шансов переобучиться.
Например, наивный байесовский метод лучше всего работает, когда обучающая выборка большая. Модели с низким смещением и высокой дисперсией, как правило, работают лучше, поскольку они отлично работают со сложными отношениями.
6. Объясните матрицу недоразумений применительно к алгоритмам машинного обучения.
Матрица неточностей (или матрица ошибок) — это особая таблица, которая используется для измерения производительности алгоритма. Он в основном используется в обучении с учителем; при обучении без учителя это называется матрицей соответствия.
Матрица неточностей имеет два параметра:
Он также имеет идентичный набор функций в обоих этих измерениях.
Рассмотрим матрицу неточностей (двоичную матрицу), показанную ниже:
Здесь,
Для фактических значений:
Всего Да = 12 + 1 = 13
Всего нет = 3 + 9 = 12
Аналогично для прогнозируемых значений:
Всего Да = 12 + 3 = 15
Всего нет = 1 + 9 = 10
Чтобы модель была точной, значения по диагоналям должны быть высокими.Общая сумма всех значений в матрице равна общему количеству наблюдений в наборе тестовых данных.
Для приведенной выше матрицы общее количество наблюдений = 12 + 3 + 1 + 9 = 25
Теперь точность = сумма значений диагонального / общего набора данных
= (12 + 9) / 25
= 21/25
= 84%
7. Что такое ложноположительный и ложноотрицательный и насколько они значимы?
Ложные срабатывания — это те случаи, которые ошибочно классифицируются как Истинно , а Ложно .
Ложноотрицательные — это те случаи, которые ошибочно классифицируются как Ложь , но имеют Истинно .
В термине «ложноположительный» слово «положительный» относится к строке «Да» прогнозируемого значения в матрице неточностей. Полный член указывает, что система предсказала это как положительное, но фактическое значение отрицательное.
Итак, глядя на матрицу путаницы, получаем:
Ложноположительный результат = 3
Истинно положительный результат = 12
Аналогичным образом, в термине «Ложноотрицательный» слово «Отрицательный» относится к строке «Нет» прогнозируемого значения в матрице неточности.И полный член указывает, что система предсказала это как отрицательное, но фактическое значение положительное.
Итак, глядя на матрицу путаницы, получаем:
Ложноотрицательный = 1
Истинно отрицательный = 9
8. Каковы три этапа построения модели в машинном обучении?
Три этапа построения модели машинного обучения:
Модель здания
Выберите подходящий алгоритм для модели и обучите его согласно требованиюТестирование модели
Проверьте точность модели по тестовым даннымПрименение модели
Внесите необходимые изменения после тестирования и используйте окончательную модель для проектов в реальном времени
Здесь важно помнить, что время от времени модель необходимо проверять, чтобы убедиться, что она работает правильно.Его следует изменить, чтобы убедиться, что он актуален.
9. Что такое глубокое обучение?
Глубокое обучение — это подмножество машинного обучения, которое включает в себя системы, которые думают и учатся, как люди, с использованием искусственных нейронных сетей. Термин «глубокий» происходит от того факта, что у вас может быть несколько уровней нейронных сетей.
Одно из основных различий между машинным обучением и глубоким обучением заключается в том, что в машинном обучении разработка функций выполняется вручную. В случае глубокого обучения модель, состоящая из нейронных сетей, автоматически определяет, какие функции использовать (а какие не использовать).
10. В чем разница между машинным обучением и глубоким обучением?
| Машинное обучение | Глубокое обучение |
|---|---|
|
|
11.Каковы приложения контролируемого машинного обучения в современном бизнесе?
Применения машинного обучения с учителем включают:
- Обнаружение спама в электронной почте Здесь мы обучаем модель, используя исторические данные, состоящие из писем, отнесенных к категории спама или не спама. Эта помеченная информация вводится в модель.
- Медицинская диагностика Предоставляя изображения, относящиеся к болезни, модель может быть обучена определять, страдает ли человек этим заболеванием или нет.
- Анализ настроений Это относится к процессу использования алгоритмов для поиска документов и определения их положительных, нейтральных или отрицательных настроений.
- Обнаружение мошенничества Обучая модель выявлять подозрительные шаблоны, мы можем обнаруживать случаи возможного мошенничества.
12. Что такое полу-контролируемое машинное обучение?
При обучении с учителем используются полностью помеченные данные, тогда как при обучении без учителя данные обучения не используются.
В случае полууправляемого обучения обучающие данные содержат небольшой объем помеченных данных и большой объем немаркированных данных.
13. Что такое методы машинного обучения без учителя?
В обучении без учителя используются два метода: кластеризация и ассоциация.
Кластеризация
Задачи кластеризации включают разделение данных на подмножества. Эти подмножества, также называемые кластерами, содержат похожие друг на друга данные.В отличие от классификации или регрессии, разные кластеры раскрывают разные детали об объектах.
Ассоциация
В задаче ассоциации мы определяем шаблоны ассоциаций между различными переменными или элементами.
Например, веб-сайт электронной коммерции может предложить вам другие товары для покупки на основе ваших предыдущих покупок, ваших привычек в расходах, товаров из вашего списка желаний, покупательских привычек других клиентов и т. Д.
14.В чем разница между контролируемым и неконтролируемым машинным обучением?
- Контролируемое обучение — Эта модель учится на помеченных данных и делает прогноз на будущее на выходе
- Обучение без учителя — Эта модель использует немаркированные входные данные и позволяет алгоритму действовать на основе этой информации без руководства.
15. В чем разница между индуктивным машинным обучением и дедуктивным машинным обучением?
| Индуктивное обучение | Дедуктивное обучение |
|---|---|
|
|
16. Сравните алгоритмы K-средних и KNN.
| К-средства | КНН |
|---|---|
|
|
17.Что такое «наивное» в наивном байесовском классификаторе?
Классификатор называется «наивным», потому что он делает предположения, которые могут оказаться верными, а могут и нет.
Алгоритм предполагает, что наличие одной функции класса не связано с наличием какой-либо другой функции (абсолютная независимость функций) с учетом переменной класса.
Например, плод может считаться вишней, если он красного цвета и круглой формы, независимо от других характеристик.Это предположение может быть верным, а может и нет (поскольку яблоко также соответствует описанию).
18. Объясните, как система может играть в шахматы, используя обучение с подкреплением.
У обучения с подкреплением есть среда и агент. Агент выполняет некоторые действия для достижения определенной цели. Каждый раз, когда агент выполняет задачу, направленную на достижение цели, он вознаграждается. И каждый раз, когда он делает шаг, который идет против этой цели или в обратном направлении, он наказывается.
Раньше шахматным программам приходилось определять лучшие ходы после долгих исследований множества факторов. Для создания машины, предназначенной для игры в такие игры, потребуется указать множество правил.
Благодаря усиленному обучению нам не нужно решать эту проблему, поскольку обучающийся агент учится, играя в игру. Он сделает ход (решение), проверит, является ли это правильным (обратная связь), и сохранит результаты в памяти для следующего шага (обучения). За каждое правильное решение, принятое системой, есть награда, а за неправильное — наказание.
19. Как узнать, какой алгоритм машинного обучения выбрать для задачи классификации?
Хотя не существует фиксированного правила выбора алгоритма для задачи классификации, вы можете следовать этим рекомендациям:
- Если точность важна, протестируйте разные алгоритмы и перепроверьте их.
- Если набор обучающих данных невелик, используйте модели с низкой дисперсией и высоким смещением
- Если набор обучающих данных большой, используйте модели с высокой дисперсией и небольшим смещением
20.Как Amazon может рекомендовать другие товары для покупки? Как работает механизм рекомендаций?
Как только пользователь что-то покупает у Amazon, Amazon сохраняет данные о покупках для использования в будущем и находит продукты, которые, скорее всего, также будут куплены, это возможно благодаря алгоритму ассоциации, который может идентифицировать закономерности в заданном наборе данных.
21. Когда вы будете использовать классификацию вместо регрессии?
Классификация используется, когда ваша целевая переменная является категориальной, а регрессия используется, когда ваша целевая переменная является непрерывной.И классификация, и регрессия относятся к категории контролируемых алгоритмов машинного обучения.
Примеры проблем классификации:
- Прогнозирование да или нет
- Примерный пол
- Порода животных
- Тип цвета
Примеры проблем регрессии:
- Оценка продаж и цены на товар
- Прогнозирование счета команды
- Прогноз количества осадков
22.Как разработать фильтр спама в электронной почте?
Создание спам-фильтра включает в себя следующий процесс:
- Спам-фильтр электронной почты будет загружен тысячами писем
- У каждого из этих писем уже есть ярлык: «спам» или «не спам».
- Затем контролируемый алгоритм машинного обучения определит, какие типы писем помечаются как спам на основе таких слов, как лотерея, бесплатное предложение, отсутствие денег, полный возврат средств и т. Д.
- В следующий раз, когда электронное письмо вот-вот попадет в ваш почтовый ящик, спам-фильтр будет использовать статистический анализ и алгоритмы, такие как деревья решений и SVM, чтобы определить, насколько вероятно, что письмо является спамом.
- Если вероятность высока, он пометит его как спам, и письмо не попадет в ваш почтовый ящик
- Исходя из точности каждой модели, мы будем использовать алгоритм с максимальной точностью после тестирования всех моделей
23.Что такое случайный лес?
«Случайный лес» — это алгоритм машинного обучения с учителем, который обычно используется для задач классификации. Он работает путем построения нескольких деревьев решений на этапе обучения. Случайный лес выбирает решение большинства деревьев в качестве окончательного решения.
24. Учитывая длинный список алгоритмов машинного обучения с учетом набора данных, как вы решить, какой из них использовать?
Нет главного алгоритма для всех ситуаций.Выбор алгоритма зависит от следующих вопросов:
- Сколько у вас данных, непрерывные или категориальные?
- Связана ли проблема с классификацией, ассоциацией, кластеризацией или регрессией?
- Предопределенные переменные (помеченные), немаркированные или смешанные?
- Какова цель?
На основании вышеперечисленных вопросов можно использовать следующие алгоритмы:
25. Что такое смещение и отклонение в модели машинного обучения?
Смещение
Смещение в модели машинного обучения возникает, когда прогнозируемые значения находятся дальше от фактических значений.Низкое смещение указывает на модель, в которой значения прогноза очень близки к фактическим.
Недообучение: высокое смещение может привести к тому, что алгоритм упустит соответствующие отношения между функциями и целевыми выходными данными.
Разница
Дисперсия — это величина, на которую целевая модель изменится при обучении с разными данными обучения. Для хорошей модели дисперсия должна быть минимизирована.
Переобучение: высокая дисперсия может привести к тому, что алгоритм будет моделировать случайный шум в обучающих данных, а не на предполагаемых выходных данных.
Бесплатный курс: алгоритмы машинного обучения
Изучите основы алгоритмов машинного обучения26. Каков компромисс между смещением и отклонением?
Декомпозиция смещения-дисперсии по существу разлагает ошибку обучения любого алгоритма путем добавления смещения, дисперсии и небольшого количества неснижаемой ошибки из-за шума в базовом наборе данных.
Обязательно, если вы сделаете модель более сложной и добавите больше переменных, вы потеряете систематическую ошибку, но получите дисперсию.Чтобы получить оптимально уменьшенное количество ошибок, вам придется найти компромисс между смещением и дисперсией. Не нужны ни высокая систематическая ошибка, ни высокая дисперсия.
Алгоритмы с высоким смещением и низкой дисперсией обучают непротиворечивые, но в среднем неточные модели.
Алгоритмы с высокой дисперсией и низким смещением обучают модели, которые являются точными, но непоследовательными.
27. Определите точность и отзыв.
точность
Точность — это отношение нескольких событий, которые вы можете правильно вспомнить, к общему количеству событий, которые вы вспоминаете (сочетание правильных и неправильных повторных вызовов).
Точность = (истинно положительный результат) / (истинный положительный результат + ложный положительный результат)
Отзыв
Отзыв — это отношение количества событий, которые вы можете вспомнить, к общему количеству событий.
Отзыв = (Истинно Положительный) / (Истинно Положительный + Ложноотрицательный)
28. Что такое классификация дерева решений?
Дерево решений строит модели классификации (или регрессии) в виде древовидной структуры, при этом наборы данных разбиваются на все более мелкие подмножества при разработке дерева решений буквально в древовидной форме с ветвями и узлами.Деревья решений могут обрабатывать как категориальные, так и числовые данные.
29. Что такое сокращение в деревьях решений и как это делается?
Отсечение — это метод машинного обучения, который уменьшает размер деревьев решений. Это снижает сложность окончательного классификатора и, следовательно, повышает точность прогнозирования за счет уменьшения переобучения.
Обрезка может происходить в:
- Нисходящая мода. Он будет проходить узлы и обрезать поддеревья, начиная с корня
- Восходящий мод. Начнется с конечных узлов
Существует популярный алгоритм сокращения, называемый сокращенным сокращением ошибок, в котором:
- Начиная с листьев, каждый узел заменяется на свой самый популярный класс
- Если точность прогноза не изменяется, изменение сохраняется.
- Преимущество простоты и скорости
30. Кратко объясните логистическую регрессию.
Логистическая регрессия — это алгоритм классификации, используемый для прогнозирования двоичного результата для заданного набора независимых переменных.
Результатом логистической регрессии является либо 0, либо 1 с пороговым значением обычно 0,5. Любое значение выше 0,5 рассматривается как 1, а любая точка ниже 0,5 рассматривается как 0.
31. Объясните алгоритм ближайшего соседа.
Алгоритм ближайшего соседаK — это алгоритм классификации, который работает таким образом, что новая точка данных назначается соседней группе, на которую она наиболее похожа.
В K ближайших соседей K может быть целым числом больше 1.Итак, для каждой новой точки данных, которую мы хотим классифицировать, мы вычисляем, к какой соседней группе она ближе всего.
Давайте классифицируем объект на следующем примере. Представьте, что есть три кластера:
- Футбол
- Баскетбол
- Мяч теннисный
Пусть новая точка данных, подлежащая классификации, представляет собой черный шар. Мы используем KNN для его классификации. Предположим, что K = 5 (изначально).
Затем мы находим K (пять) ближайших точек данных, как показано.
Обратите внимание, что все пять выбранных точек не принадлежат одному кластеру. Есть три теннисных мяча и по одному для баскетбола и футбола.
Когда задействовано несколько классов, мы предпочитаем большинство. Здесь большинство связано с теннисным мячом, поэтому новая точка данных назначается этому кластеру.
32. Что такое система рекомендаций?
Любой, кто использовал Spotify или делал покупки в Amazon, узнает систему рекомендаций: это система фильтрации информации, которая предсказывает, что пользователь может захотеть услышать или увидеть, на основе шаблонов выбора, предоставленных пользователем.
33. Что такое Kernel SVM?
Kernel SVM — это сокращенная версия векторной машины поддержки ядра. Методы ядра — это класс алгоритмов анализа паттернов, и наиболее распространенным из них является SVM ядра.
34. Какие есть методы уменьшения размерности?
Вы можете уменьшить размерность, объединив элементы с проектированием элементов, удалив коллинеарные элементы или используя алгоритмическое уменьшение размерности.
Теперь, когда вы ответили на эти вопросы на собеседовании по машинному обучению, вы, должно быть, получили представление о своих сильных и слабых сторонах в этой области.
Получите обзор концепций ИИ, рабочих процессов и показателей производительности на курсах сертификации ИИ и машинного обучения.
Станьте частью кадрового резерва машинного обучения
С развитием технологий рабочие места в области обработки данных и искусственного интеллекта будут по-прежнему востребованы. Кандидаты, которые повышают свою квалификацию и хорошо разбираются в этих новых технологиях, могут найти множество возможностей трудоустройства с внушительной зарплатой. В зависимости от вашего уровня опыта вас могут попросить дополнительно продемонстрировать свои навыки в машинном обучении, но это в основном зависит от должности, которую вы преследуете.Эти вопросы и ответы на собеседование по машинному обучению подготовят вас к успешному прохождению собеседования с первой попытки!
Учитывая эту тенденцию, Simplilearn предлагает сертификационный курс по искусственному интеллекту и машинному обучению, чтобы помочь вам прочно закрепить концепции машинного обучения. Этот курс хорошо подходит для тех, кто находится на среднем уровне, в том числе:
- Менеджеры по аналитике
- Бизнес-аналитики
- Информационные архитекторы
- Разработчики, желающие стать исследователями данных
- Выпускники, желающие сделать карьеру в области науки о данных и машинного обучения
Ответить на вопросы собеседования по машинному обучению станет намного проще после завершения этого курса.
.